Hi @redvivi
Great plugin, works well and super easy to use!
Unfortunately all files (only .jpeg and .png images) that are uploaded to my S3 bucket are saved there with metadata “application/octet-stream”. When accessing the file in the bucket, the header includes this metadata, which makes the files unusable for most other applications.
Can you update the plugin so the right Content-Type Metadata is applied to files that are uploaded (e.g. image/png in my case).
As Mime-Type detection is not foolproof, we have just added “Content-Type” as a dynamic input parameter to our plugin action, so you can either set it manually, or using the following plugin to detect the Mime-Type.
Should you need further assistance, we are always here to help!
How would I view the file that the plugin gets? I am getting the datastream and also tried the datastream’s URL and datastream saved to s3 and nothing shows up in the pdf viewer despite the file being a pdf? The situation is that I have a private S3 bucket and want to display the file in my bubble app after getting it with your plugin. How would I go about this?
I can get the raw unusable data stream but cannot get any values when I select file name, URL or saved to s3. So I know the plugin is connecting to AWS, I am just unable to make any use of the retrieved file. The only ones giving any data is the datasteam and the datastream URL (which is not a URL, but the raw datastream itself). Not sure how the get function is useful at all??
It might be helpful if the plugin included the ability to pre-sign a file URL so it can be viewed within Bubble or publically if required.
It mostly depends on the front-end elements you are using.
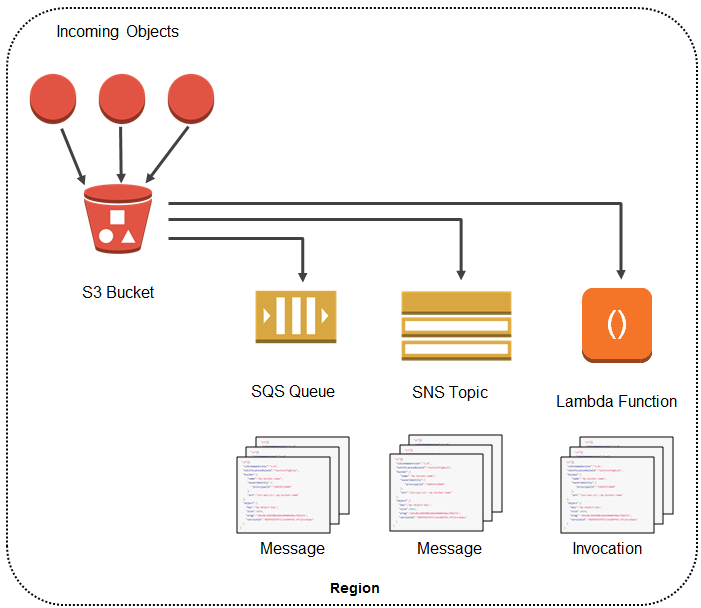
For instance, raw data returned by the Get File from S3 plugin action may be directly used by audio player elements, so you can use this action to directly retrieve audio-stream from AWS S3.
If the front-end element is only supporting URLs (and not data-URI) as input parameter, then the best is to reconstruct the AWS S3 file URL from the URN output of the Put File to S3 plugin action, as per the plugin documentation:
Of course this would require to set your AWS S3 Bucket as “semi-public”, e.g. allowing anybody to Get a file given its URLs, but NOT List the content of the bucket, so only the URLs known to the user are accessible.
Should you require pre-signed unique file URLs (keep in mind that these pre-signed URLs are only valid for a specific period of time, so they would mostly need to be generated prior to each retrieval), please reach us directly in DM, we would be happy to customise the behaviour to meet your use-case.
Thanks for your message and apologies for the time to answer.
Should you want to upload more files, we would recommend to loop on a list, there is a plugin called Simple looper (workflow repeater) that may be useful on this.
We have implemented this workflow repeater on another demo editor, but the principle remains the same: You construct a list of URLs and file names, and any other parameter that you want to take pass into the Put File to S3 action.
Maybe I didn`t understand well or I did not explained the question very well too.
Is there any way to upload more than one image when you click in the upload box just once? (Like when you use the multi file upload)
let`s say I have 20 pics:
I need to repeat again and again 20 times (click on the upload image > open the search box in my computer > select only one image) instead to click in the upload image one time and then show me the search box in my computer that i can select 20 pictures to upload just once.
The loop works for this situation?
Can I use multi-file to upload the image?
The multi-file uploader works with your plugin to put a list of url`s on my S3?
(it would be great if it worked like that. it is a very good improvement)
As mentioned before, the way to achieve this would be to create a repeating group of file uploader elements. You will still need to select each image individually to populate each file uploader elements.
Your repeating group consists now of a list of file uploader elements, referring to your images, then using the looper plugin, you can trigger a workflow to loop on this list. So with one click on the upload button, you upload all the images.
If this does not suit your use-case, please reach to us via DM for further assistance.
I’ve read up on the docs, but I’m not sure how to actually use this efficiently. Can you include WHY A PRESIGNED URL WOULD BE BENEFICIAL, and an actual “demo/use-case” for it?
Also, maybe a demo on how to display said files or list said files. I keep getting a “403 Forbidden” error when I try to view the file after I upload to a bucket. The buckets settings are even 100% public and it still says it.
Maybe I’m stupid and their is some resource out there to explain my issues, but I am here and using your plugin, so if you could explain how to utilize it to the “noob” type people like me, that would be great.
My goal is a user uploads a file, and they can view it along with others. The other thing is possibly explaining how we can setup the permissions correctly. All you state is add credentials to api. That’s not much in explanation. I tried everything, and I just cannot figure out the issue.
An explanation of the benefits is included in the Instructions section, but perhaps it is not exactly what you expect:
GENERATE PRESIGNED EXPIRING URL generates an URL allowing access to the specified object, expiring after the specified duration. The presigned URLs are useful if you want your user/customer to be able to download a specific object from your bucket, but you don’t require them to have AWS security credentials, permissions, nor bucket public access.
Using presigned URL (which always expire) is available on the demo of our plugin : AWS Utilities Plugin Demo
A current limitation of the AWS implementation of the presigned URL is that it doesn’t check if the file actually exists before generating the URL, which means that if you enter a wrong filename, a presigned URL will be generated but as the target file doesn’t exists, will always end up in 403 (note: that’s definitely something to be improved and we are taking note of this for our roadmap).
That would explain as well why you do still encounter this error despite your bucket being public.
Okay, so wondering if you can RETURN an uploaded files FILE SIZE?
I need this cause I compress with another service, then upload to S3, then update my DB with the new link. I’m not able to return the updated filesize anywhere. If you know of another work around, that’d be great. I’m up for even adding custom JS if I need to.
Yes, the file size limits are stated in the plugin documentation: AWS S3 Dropzone & SQS Utilities Plugin | Bubble
These limits exist as this plugin uses server-side action which have a max execution duration.
Using the AWS S3 Dropzone element of this plugin @MarkusBoostedApp , there are 5GB file size limit.
Also, this plugin has the advantage to allow to use AWS S3 backend actions without relying on any user trigger.