Page of ‘daily jobs’ sorted into 12 repeating groups (all taking data from 1 hidden repeating group).
Each section of the job requires 1 truck, 1 driver and 2 trailers. There can be up to 3 sections in each job.
Total of 3 trucks, 3 drivers and 6 trailers allocated to any one job.
I’m trying to work out an efficient way to highlight all duplicate values shown in a repeating group (for example, a truck from one job is also allocated to another job). In the past I had run a search in the database, and then using the :count function basically said if there was more then 1 found for a certain date then conditional formatting would highlight it red.
This slowed down the page dramatically (which is already rather heavy in terms of workflows and data), resulting in having to remove it from the page.
I’m hoping there is something I can run based on the hidden repeating group?
I think the best thing to do here is share a link to your app with your data if you’re ok with that. It’ll be easier to investigate how you have things set up and prescribe solutions!
At the moment I want to know why all the RGs need to be sourced from a hidden RG and not directly from the database. Also want to see how many items per RG you’re loading up at once because that alone can affect performance. Also if you’re using the filter modifier rather than filtering within search constraints…
I actually initially had all the repeating groups sourcing from the database, however I was encouraged to restructure based on the hidden repeating group from this post; Any ideas on speeding up read/write to database? in order to help speed the page up.
In terms of performance, its not too bad right now - much better then previously. If you have any ideas on how I could structure it better I’m all for it!
Unfortunately, given the complexity of some of the searches I have to use the filter modifier (which was pointed out to me in another post). The hidden group currently searches for all of the stuff each repeating group has in common - and then each of the 24 (yes, 24 repeating groups!) filters based on that information.
Here is a link to the public app I just created - [removed - please ask for the link] - including the data (though I may remove it given some of its sensitive nature - this app is currently live in our organization).
EDIT: Also, if you struggle loading up the editor - add &issues_off=true to the end of the URL. The crazy amount of stuff going on in the page means that the issue checker goes nuts and will lead to huge performance issues (in my experience anyway).
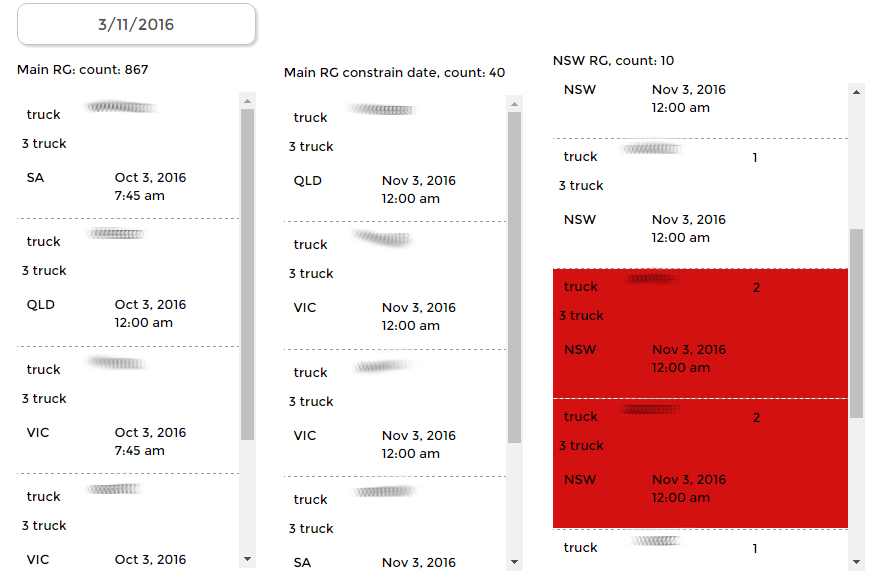
Hey @luke, I loaded it up fine. So, I’m looking at Victoria/New South Wales/Queensland RGs. You want to, for example, be able to identify trucks in Victoria that are also used in NSW & Queensland OR are you wanting to identify trucks that are duplicated within Victoria itself?
If a truck shows up twice in Victoria, it needs to be highlighted. If a truck shows up in Victoria and in Queensland it also needs to be highlighted.
I’m thinking that instead of searching the data like I previously had, maybe there is a way I could highlight values that are the same (on the surface level without having to touch the database).
Ignore the intransit RG’s for the moment (the bottom 3 RG’s for each state).
Would it be more efficient to constrain the “Allocation RG Main” with the date in “Main Date Selector”, or are there some RG’s using the data without that filter?
I recommend making another simpler page (hidden from end users) to experiment with finding duplicates.
Yeah unfortunately I’ve used both of these and they slow the page down dramatically (though since restructuring to using a hidden repeating group I haven’t tried). I believe it comes down to the sheer number of repeating groups having to run the search every time data changes.
I’ve just set up another search elsewhere to test and it has a lag (testing for count > 1)
Surely there is a way to format based on the hidden group housing all the data? I’ve been playing around but just can’t get anywhere!
Your probably right! The in-transit loads would need a separate hidden group (not a big deal) as they are based on past dates, though then the repeating groups would have to wait for the Main RG to search and THEN filter, as opposed to just having to wait for a search.
If there was a way for me to search based on the main date selector that would be great (as opposed to filter), but it doesn’t seem to work!
There’s also a start date 2 and start date 3 for the second and third legs which makes things even more complex. I like your idea from before about filtering the Main RG based on the Date selector instead of each RG doing it seperately - I’ll just create another hidden group for the In-transit loads.
Unfortunately this is the same for the duplicates! There is also a truck 2/3 that needs to be accounted for. I’ve done some playing around, and I think I may have a solid solution. I’ve basically created a consolidated ‘thing’ [named Utilizations] for allocations (completely separate).
It takes truck 1, truck 2, and truck 3 from an allocation and creates a consolidated ‘truck’ thing for each that also has a date and allocation ID. For example;
Truck 1 will become Truck; Date; Allocation ID
Truck 2 will become Truck; Date; Allocation ID
Truck 3 will become Truck; Date; Allocation ID
Basically they become 3 seperate ‘Utilizations’ with their own appropriate start dates and Allocation ID (which would be the same for all 3).
That way they are all put into the same dataset and can be easily compared for duplicates! I haven’t completely tested this yet, but it appears to be promising so far.