Hi, I have a scheduled backend API workflow that runs every hour that checks a message queue and handles sending the appropriate messages if there are any. This scheduled task seems to die about once per week and I never know when it’s happened. The only way I know is by noticing absence of messages at which point I login to the app editor > Logs > Scheduler and confirm that it has in fact stopped. I then have a hidden password-protected page in the app that I have to navigate to and click to relaunch the scheduled task.
Is there some more robust way of handling this scenario and auto-restarting scheduled processes that die? The conundrum is that anything I build in bubble as a scheduled task will be inherently subject to whatever glitch caused the process it’s monitoring to die… How do others handle this? Do you have an external tool like Uptime Robot (or some equivalent) hitting a page monitoring for the liveness of that process somehow and then having it conditionally trigger the restart of the process once it detects that it’s died? Seems super jhankey and just wondering what others are doing for this.
I personally log everything around scheduled tasks and include status’s.
Ex sending an email as a scheduled task at a certain date and time.
When scheduled it changes status from draft to scheduled and fills a field for schedule date.
Since the send is a multi action workflow it changes status to pending at the first step so I know WF started.
After send it changes status to sent only if response from email provider was success. If not it logs the error and emails me.
In admin dash I have a box that displays everything but success data.
Secondly in admin dash I have a box that displays any emails that scheduled date < current date & status is not sent. This way I can catch any one off errors that may have not got logged all together.
(To return api errors it’s important to check the box that allows the workflow to continue even if action fails in api connector/plugin builder. This way you can save the error from the API provider and know what happened)
Chris, thanks for your response. Whether I monitor a dashboard of statuses in the app or the scheduled task list in the Bubble editor to see if it’s still running, either of those approaches require me periodically manually logging in and looking at something then restarting the service if it’s failed. Ideally I’m looking for something I can put on auto-pilot that will just babysit it and assure that scheduled task is always running and restart it if it fails.
I’m going to play around with making a kind of “canary” service that I can hit externally with an uptime monitor service like Uptime Robot that’s not reliant upon Bubble’s scheduled task system to run. I’ll try and make it so if it ever detects the service has died that it then automatically restarts it. I’ll report back if I can get something generic enough that it’s useful for others. I was just wondering if someone had already made a plugin for this purpose but maybe it’s too specific a usecase. Anyways thanks for your suggestions.
OK so here’s the setup I came up with (it’s fairly simple and elegant). For now it doesn’t auto-start the failed scheduled task, just alerts me when it’s been down beyond a certain interval. And given that it’s based on an external monitoring service it should be immune to the catch-22 of using a scheduled task to monitor a scheduled task. So here’s how it works:
Every time my message queue process runs it sets a field in the db called “LastSuccessfulMsgQueueClear” to CurrentDatetime.
I then have a page called /monitor which on it has a piece of text that says “Up” with this conditional on it:
Basically everytime the monitor page is loaded it calculates the delta of now vs. LastSuccessfulMsgQueueClear time and if ever it exceeds the allowable downtime limit (which I set to 60min for now) then it changes the text from “Up” to “Down”
Lastly, I created a free monitor process on UptimeRobot of type “keyword” with these settings:
So if ever it finds the word “Down” on that page it will send an alert.
For now it’s purely passive monitoring to catch this process when it dies and send an alert so I can manually kick it.
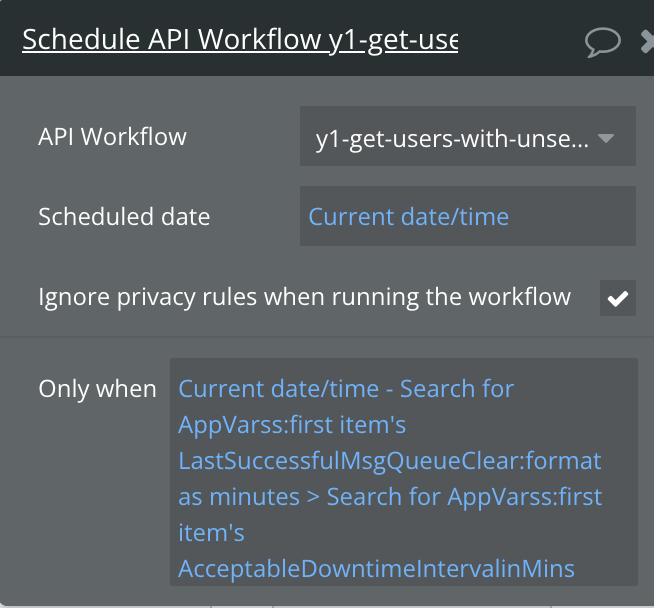
To do an auto-restart, the next iteration I believe would just involve creating a backend db trigger that says “when the delta of now vs. LastSuccessfulMsgQueueClear > AcceptableDowntime, Schedule API task MsgQueueClear time = CurrentTime.”
Update: so I just discovered the above solution doesn’t actually work with Uptime Robot because of the way that Bubble pages are rendered (UR requires that the keyword be present in the HTML source of the page being monitored and Bubble just generates js which dynamically pulls in the elements of the page to construct it in the browser).
So seems like a few options here:
Switch to one of the paid monitoring services like Pingdom or Uptime.com that has the option to use headless browsers to monitor the actual page output. AFAIK there are no free monitoring solutions that do it this way because it’s more cost-intensive vs. monitoring static HTML.
Create a backend workflow using the same detection logic and then have that actively invoke the alert.
#1 costs money. #2 suffers from the conundrum that the application is then monitoring its own uptime which seems inherently flawed… For now I’ve setup #2 and rather than create an alert I’m having it auto-restart the failed service. I’ll report back if this works or not. Seems like there’s definitely room for Bubble to make some simplified app health check and alerting feature.
Update 7/31/23: I learned that a backend workflow of type = “database trigger” will not actually fire with the logic I was using to detect that the Message Queue processing task was no longer running.
I’ve converted this from a Trigger → Scheduled API workflow
and used the same detection logic to restart the service via that:
I setup a recursive workflow that runs this check and then reschedules itself every hour for now. This should hopefully be the last iteration here and result in a self-healing system that restarts key Scheduled API tasks that fail. I’ll report back to verify once I have proof of this being the case. For now this seems to fail about once every other week with current site traffic.
Update 10/5/23: so I just wanted to close the loop on this thread because it’s been a super interesting exercise and I finally have the grail with “self-healing” processes.
I can confirm that after two months of using the method i proposed above it has had zero downtime. The only Achilles heel here is that I’m using a Bubble scheduled task to monitor another Bubble scheduled task so if Bubble’s cron mechanism goes down all bets are off here. I believe the last missing piece here is to setup Uptime Robot on a page and just have the global uptime monitor for the app itself handled via that. Anyways this solved the pressing issue which was certain scheduled tasks just disappearing intermittently and having no means to know it was down. Very happy with how this ^^ last solution worked out.