We’re still using the same API call to the OCR service, so there won’t be any changes in text extraction. However, this update enhances the security of the API keys, and we strongly recommend everyone update the plugin!
The only changes you’ll need to make are to add the API key in the plugin settings and replace the previous action with the new one.
Please let us know if you have any further questions!
Thanks for reaching out to us and we apologize for the delayed reply
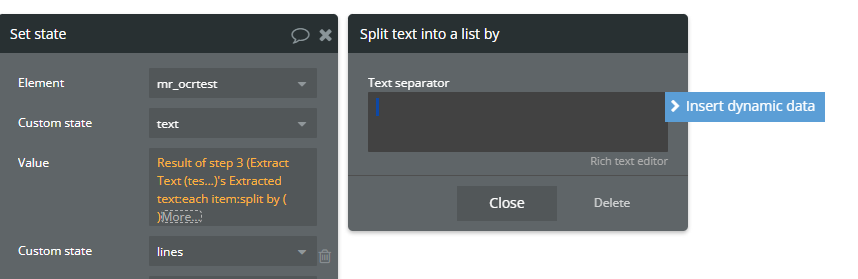
The extracted text from the image comes as the result of the “Extract Text” action. To simply save the result, you can set them as a custom state.
To explain more, as you mentioned you’re new to this, the “Extract Text” action can return information. After adding the extract action to the workflow, you can add a "Set State of an Element” action. In this new action, select a custom state you created. When setting the value of the custom state, you’ll have an additional dynamic option: “Result of step X”. Choose what information you want to set to the custom states like this example.
You can also check our demo page to see how the extracted text is saved
Let us know if you have any other questions or concerns!
Good question! The extracted text is a list, but if you’re seeing :count as 1, it likely means that the OCR engine returned the entire text as a single list item instead of breaking it into multiple lines.
To retrieve a specific line, you can try:
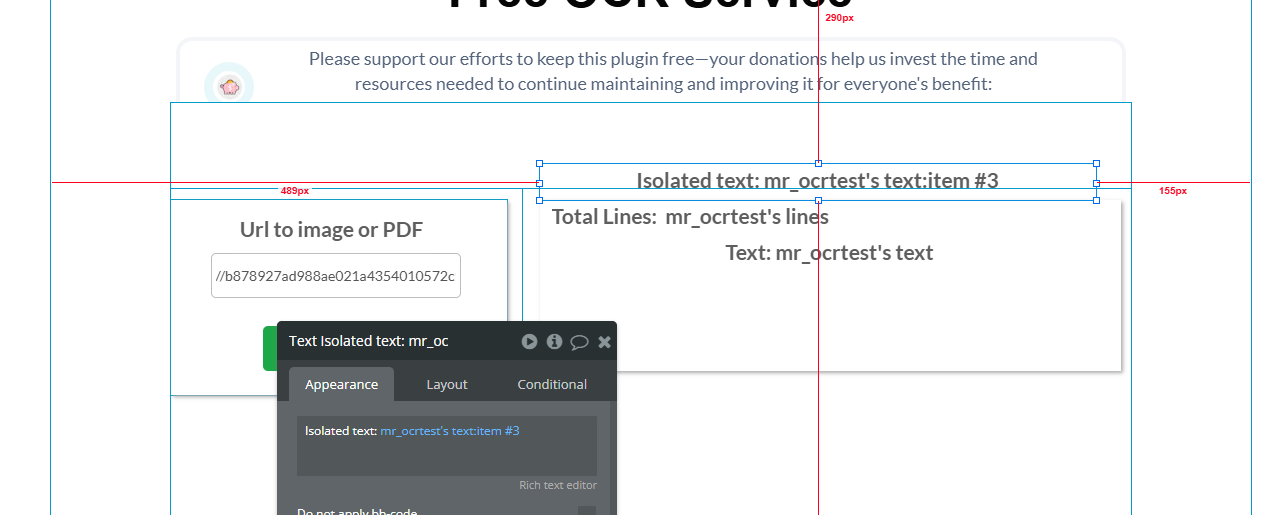
Splitting the text manually – Use :split by (\n) to separate the lines if they were returned as one item. Getting a specific line – Once split, use :item #3 to get the 3rd line, for example. Retrieving the last line – :last item will get the final line from the list.
You can also test different images and setups on our demo page here: OCR Test Page
Thank you for your message and apologies for the delayed response over the weekend!
Good catch! You’re right—you need to use :first item before :split by (\n) to properly break the text into separate lines.
If your expression is still returning the whole text instead of splitting it, here are a few things to check:
Ensure the text contains actual line breaks – Sometimes, OCR output might use spaces instead of \n for new lines. Try copying the extracted text into a text editor to check if line breaks exist.
Confirm the \n separator works – If \n isn’t splitting the text, try using :split by ( ) (a space) or :split by (,) if the text uses commas instead.
Debugging step – Before selecting a specific line, test the split list using a Repeating Group or a Text element (set to display the full list) to confirm that the split actually worked.
Final format – The correct approach should be:
To get the 3rd line:Popup OCR's OCR-text:first item:split by (\n):item #3
To get the last line:Popup OCR's OCR-text:first item:split by (\n):last item
Since this involves Bubble logic and implementation, please note that we provide general support related to plugin functionality and bug fixes. If you need more in-depth guidance, feel free to check the Zeroqode Forum or the Bubble Forum, where other users and experts might share additional insights.
Hope this helps! Let me know if you need anything else.
We’ve just tested this on our test page (demo link) and confirmed that splitting by space (" ") works, while \n and , do not seem to apply as expected. Please find the attached screenshots for reference.
If it’s still not working on your end, we recommend:
Testing with a Repeating Group or a Text element to display the full list of split items before applying :first item or :item #.
Trying a manual test by inputting a multi-line text string instead of OCR-generated text to see if the issue is specific to the data source.
Also, just a quick reminder that we provide general support related to plugin functionality and bug fixes. If you need advanced implementation assistance, we encourage checking the Zeroqode Forum or Bubble Forum, where other users and experts may share additional insights.
As mentioned earlier, the accuracy of OCR extraction depends on several factors, including image clarity, text contrast, and background noise. In my test, cropping the image helped improve recognition, which suggests that the original image might contain elements affecting detection.
We’d recommend trying the following: Crop or enhance the image to improve text contrast. Test with a different image to compare results. Check if any extra spaces or hidden characters are affecting the split function.
We’ve tested the OCR extraction across different devices, including iOS, macOS, and Android, and the results have remained consistent. This suggests that the variation you’re seeing may be due to differences in browser rendering, image processing, or specific conditions on your device.
To help narrow this down, could you let us know: Which device/browser you’re using? If any browser extensions or settings might be interfering? If the issue persists when using a different browser or incognito mode?






{kind=link}
{kind=link}
{kind=link}
{kind=link}