I’m building an app where Users are presented Questions which they answer by submitting Uploads (audio or video of them answering Questions). Other Users can then Review the Uploads.
Relevant data types are: User, Question, Upload, Review.
Users may answer over 100 questions, submit over 100 uploads, review over 100 uploads.
Now it’s time design the database and workflows for when a User submits a Review and I’m not sure how to best proceed.
A few different approaches I’ve been toying with:
• New joining table with three fields: Reviewer(user), Review, Upload
• New joining table with five fields: Reviewer(user), Reviewee(user), Review, Upload, Question
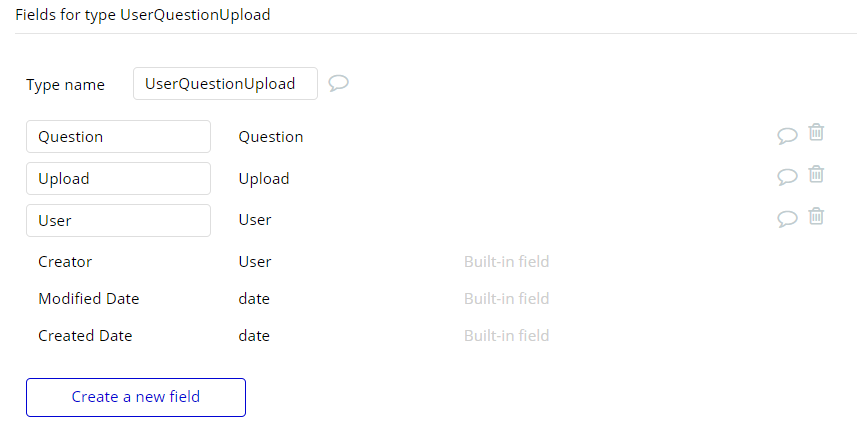
• No new joining table. Modify existing UserQuestionUpload joining table to have a Review field.
With the first approach I keep the new joining table small. But it may cause database queries to have to traverse an extra table.
For example, let’s say I’m looking at a Review and want the email of the User who submitted the Upload that was reviewed. I’d have go from: Review joining table > Upload joining table > User who created the upload.
With the second approach I could cut out a step: Review joining table > User who created the upload.
However, with the second approach, the database seems to be bigger than needed. There is redundant info on the Review and Upload joining tables.
The third option seems to reduce the amount of redundant info in the database but make my workflows more complex. In this scenario I use a single joining table. When a User creates an Upload a thing is created on the joining table and the Review field is left blank. When that Upload receives its first Review the Review field is populated on the joining table. When that Upload is subsequently reviewed a new thing is created on the joining table with all relevant fields populated from the start.
Are there other options? Other tradeoffs to consider? What approach would you choose?
With Bubble, I would encourage you not to worry about (or think in terms of) joining tables. Instead, think in simpler terms: what is the object being manipulated? Here, it looks like the Question is the object. You don’t need another User object because each object already has a Creator. Thus, to manipulate anything to do with the object’s Creator, you will access Question’s creator.
Now, it looks like while each question may have only one Creator, there may be one or more than one reviews.
So create a type Review, having sub-types ReviewBody (text) and Reviewer (user). Then, under Question, you can add an object called Reviews, which will be a list of Review.
Now to manipulate anything to do with an object’s reviews, you can access Question’s Reviews.
Finally, for each user, create a subtype Questions (list of question) and Reviews (list of Review).
In this way, you can find reviews and questions associated with a user, or reviews associated with a question.
It will save you a lot of time and effort if you look at Bubble’s clone tutorials (FB clone, Instagram clone, Quora clone, etc). Especially the Quora clone. I strongly recommend it.
As for redundancy, embrace it. The greater the redundancy, the faster your fetches, and faster your page load.
The app works slightly differently than you’ve outlined. But where you use “Question”, if I substitute “Upload”, then it makes sense.
under Question, you can add an object called Reviews, which will be a list of Review.
When you say object, do you mean a Field or a Data Type? Not 100% sure.
I think you mean a Field but if that’s the case, wouldn’t I run into the problem addressed in the Bubble Manual on the topic as an Upload could have 100, 500, 1000, 10000, or more Reviews?
Here’s exactly what the Manual says on that topic:
If a data type has a list of things for a given field, that list maxes out at 10,000 entries. This may seem like a lot, but imagine, for example, how many Pinterest posts one User might heart over their lifetime! Option 1 or 2 would break at that scale, but Option 3 would handle it fine. In practice, if you’re creating this kind of relationship and expect one thing to have a list of more than 100 values of another thing, we recommend going with [joining tables] .
As for redundancy, embrace it. The greater the redundancy, the faster your fetches, and faster your page load.
That’s the direction I was leaning. Storage is cheap so redundant data in the database is not a big problem. And if it can make my database faster to retrieve data then that’s a big plus. Glad to hear someone else validate the idea though as I’m new to database design and still learning.
Thanks again for the reply. Let me know if you have any thoughts on that excerpt from the Bubble manual.
Sorry for the rambling reply, but you got what I was trying to say
Also, the 10,000 is not a limit on the number of records of a type. It is a limit on a list within a type. So you can have a million users. But no single user can have a list that includes more than 10,000 things (say list of Uploads of one user).
In my opinion, not sure why a joining table would be needed here…
Question stands on its own
In Upload, have fields for User (person who submitted) and to Question (for the question it’s answering)
In Review, have fields for User (person who submitted) and Upload (for answer it’s reviewing)
At least this is the way I would have constructed it. You don’t hit any “list” limitations that way, it’s scalable, and it vastly simplifies your setup. I’d recommend setting up a test structure and testing it for speed, etc. before going all in.
I’ve always thought of a Thing as a row in a table with some metadata (e.g. creator, mod date, create date, unique id) and corresponding field data.
Bubble Manual says: “A thing, in Bubble, is an entry in the database. For instance, a specific car created by a user.”
I guess when I create a field in Bubble that field is an entry in a database so it’s a Thing but then what isn’t? When I create a data type that data type is an entry in a database so is that a Thing too? What isn’t a Thing?
And I’m still not sure what deadpoetnsp was referring to. You say he was referring to a Thing. But then point out a Thing can be a Field. Bubble manual also says it can be a car (with many fields such as year, make, model, etc). So what was deadpoetnsp was referring to? A field? Or a something with many fields (like a car or, in my case, an Upload)?
Is the reason a joining table isn’t needed is because there aren’t many to many relationships? E.g. an Upload answers a single Question. A Review critiques a single Upload.
I guess what you propose makes sense but I’m having trouble creating some of the more complex queries I need with this approach. Not saying it can’t be done - I just can’t figure out how to do it.
For example, I have a Progress page where users can track their progress.
Some text fields on this page are easy to populate (e.g. Upload Count: Current User’s Upload List:count).
But some I can’t figure out how I could make with the schema you describe. A few examples:
show the total number of Reviews current user has received across all their Uploads
for each Question assigned to current user, show (1) # of Reviews current user has received and (2) the highest rated (Reviews have 0-5 star rating field) Upload the user has submitted for that particular Question.
I’ve been working on this since I originally posted and the only way that I’ve been able to get these more complex queries to work is to add fields to my Upload and Review data types. By this I mean when I create an Upload I add all the Question data (question prompt, question category, sub-category, etc) to the Upload. And then when I create a Review I add all the Question and Upload data. So a Review thing will have all the info I need to answer lots of queries.
Hi, not sure I’m following everything you’re trying to do. But the basic concepts/principles I’ve used so far when structuring data are below. I’m not an expert in this stuff nor do I know the details of your project, so take the below as a download of my thinking rather than a direct recommendation…
In databases, joining tables are used for “many to many” relationships. I believe that what you have are all “one to many” relationships. (Side note: in Bubble, you don’t need a joining table for a many to many relationship, since you can link datatypes together and click the list checkmark which creates the many to many relationship. I’m sure there may be some reasons to use joining tables in Bubble, but I haven’t yet needed them thank goodness, because I expect they’d add complexity.)
In Bubble, if you were to link two datatypes together, you can link them one way (either side) or both ways. For example, let’s say one has a blog, with datatypes of Articles and Authors. For an Article, you can have Author as a field, referring to the Author datatype. Or, for an Author, you can have a field linking to the Article datatype that contains a list of all the Articles written by that Author. Or, you could link them both ways.
Which way you go comes down to speed vs. scale. You’ll see this argument discussed in threads on performance, including a great performance Q&A with Josh that is required reading. Scale says to have Article contain the Author. That way you could have a huge number of articles. Speed says to have Author contain the list of Articles. That’s because telling Bubble to list the Author’s articles is quicker than asking it to do a search for all the Articles written by an Author. However, Bubble says not to list too many Articles for an Author entry or you have performance issues. (Note: in that performance Q&A, Josh says that Bubble executes the search for all the Articles by an Author server side, which is pretty fast, so to not worry too much about it).
Database design principles also say to “normalize” your data by putting information where it belongs. So, for example, an Author may have a bio, location, etc. That info should reside in the entry for an Author, rather than duplicating it in the entry for every article the Author has written. This keeps things clean and avoids duplicating data, and if you had to update an Author’s entry, you wouldn’t have to then also update a bunch of article entries. The caveat to this with regards to Bubble is that if you need to search and filter Articles based on information in the Author entry (like, show me every article written by an Author who resides in Seattle), that may not be a fast search on Bubble since it involves two searches in your search setup: Search for all Authors in Seattle and then search for all articles written by those authors. (Note: this is where database indexing comes in, which is a whole other topic in terms of when Bubble indexes data and when).
So a key question is the extent to which scale enters the equation. For me, scale is important, so when I’m structuring all my data, I build for scale and according to database best practice, and if I run into an issue related to search speed then I deviate.
I’ve also found all the threads and discussions/arguments on these topics helpful because they tease out the different approaches and issues people are having. So, a variety of perspectives are good.
A Thing (capital t) is a custom data type created by the Bubble programmer user. (What isn’t a Thing? An object that is of a non-custom (“built in”), primitive data type. These are the data types known as text, number, numeric range, date, date range, date interval, yes/no, file, image, geographic address, the special value “empty”, or arrays (lists) of such objects. Any other data type is a Thing.) There are only a few additional things to know about Things:
An instance of a Thing can only be created by interaction with the database. (We cannot create a Thing in the page without interaction with the database.)
A Thing can only be created, modified, or deleted by the Bubble programmer user by explicitly calling the Create/Make Changes/Delete a Thing actions. Plugins cannot perform these actions.
Indeed, the Bubble database can only store and Search for Things. Any primitive data types stored in the database are stored in fields on a Thing and are stored/modified/retrieved by reference to a Thing. While a Search can be made to destructure or map the resultant Things to some component field on the Thing before returning those results to us (for example, we might do an unconstrained Search for Users:First Name), the Search itself is for Things (Users in our example) and the mapping to the text field First Name is a subsequent operation (that we might instead choose to do in the page later).
There is one built-in Thing that all Bubble projects have: The User data type. Though you cannot delete this data type it is not a primitive data type, but a Thing.
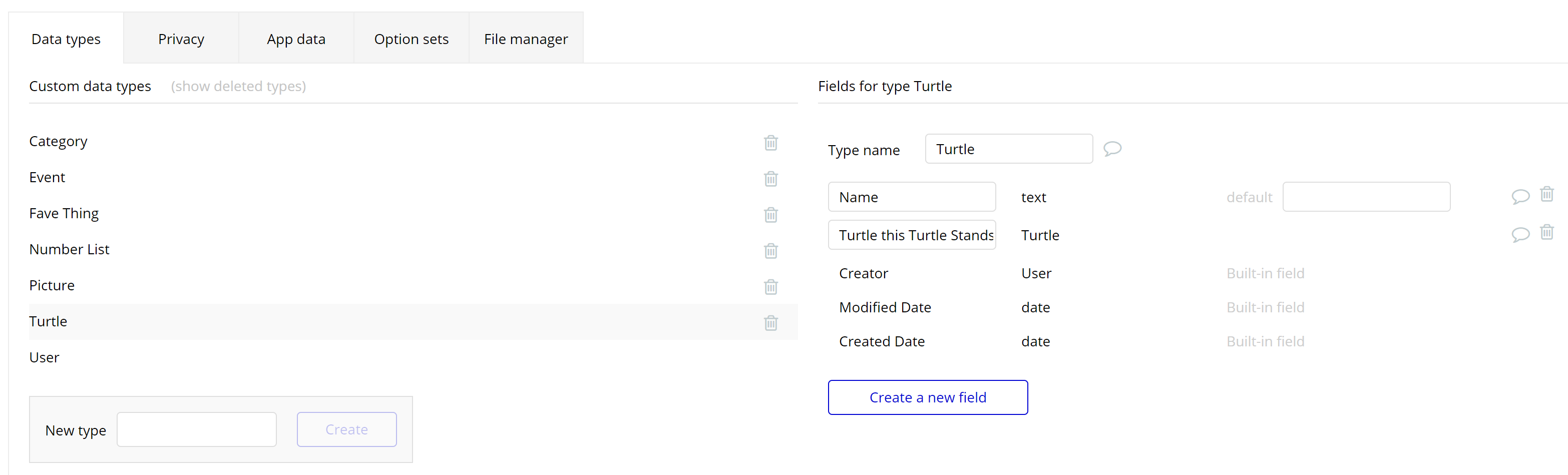
A Thing can have practically any number of fields on it and these fields can be scalars or lists of any data type including other Things or even a Thing of the same data type. (As a common example, our User object may have a list field of type User on it called Friends.) Note that some specific Thing can even refer to itself via a field of that same data type, which lets us model the very structure of the Universe:
But also, I think the above shows why you should stop thinking about your database in terms of “rows”. There’s no such thing. The only thing you should care or think about with respect to your database are the Things it contains (which are simply JavaScript objects) as this is all that you can make and all that you can access.
In my last paragraph I describe duplicating Question data on Upload and then duplicating Question and Upload data on Review.
In my gut, with the proper relational database design I don’t think I should have to repeat data (though I’m struggling to figure out how as I make clear below).
And ed727 raises a good point when he says that duplicating data can lead to issues when a record is edited. If a Question Thing were modified, I’d have to trigger a cascading series of edits of all affected Uploads and Reviews. That sounds like it could be a difficult system to maintain.
Have you had success maintaining a database structured in this manner? Is it not too difficult in practice?
Is there are reason you don’t do both? If you were to use an Author field on Article data type and have a list of Articles on the Author data type wouldn’t that give you the best of both worlds?
Were your database structured in that manner it seems to me you’d have both the speed and scale options available and you could choose whichever was more appropriate for each individual database query.
I realize this violate your principle of normalization but with normalization I seem to be running into the multiple search issue you address:
In my example I have a Question, Upload (think “answer” data type), and a Review data types.
One question has many Uploads. One Upload has many Reviews.
Let’s say Current User has submitted two Uploads in response to the Question in which we’re interested. And each of those two Uploads have received five Reviews. So one Question, two Uploads, 10 Reviews.
For that one Question, I want to show the Current User’s Upload with the highest average Score (Score is a field on Review).
For the Current User and the relevant Question, let’s say Upload 1 has Scores of (3, 3, 4, 5, and 5 for an average of 4) and Upload 2 has Scores of (4, 4, 4.5, 5 and 5 for an average of 4.5). Upload 2 is the higher rating and that is the Upload whose score I want to show.
With a “normalized” database structure, I can’t figure out a way to do this without doing a ton of searches and/or running into dead ends.
First I do a search for Uploads where Question is the relevant question and Created By = Current User.
Then I get lost. I need to find all of the Reviews associated with the list of Uploads. Uploads doesn’t have field for Review (only Reviews has a field for Uploads in a “normalized” database) so I don’t know how to get the list of Reviews for this User / Question combo.
Even if I could get the list of relevant Reviews described in step 3, then I’d have to perform math on those Reviews. Each Upload has five Reviews. I’d need to average the Review’s rating field at the Upload level and return the Upload with the highest average rating.
Maybe I’m approaching this wrong and shouldn’t start with a search for Uploads where Creator = Current User.
Since Review has a field for Upload but Upload doesn’t have a field for Reviews maybe I need to start with Reviews to get around this problem. But this seems to create it’s own unique problems.
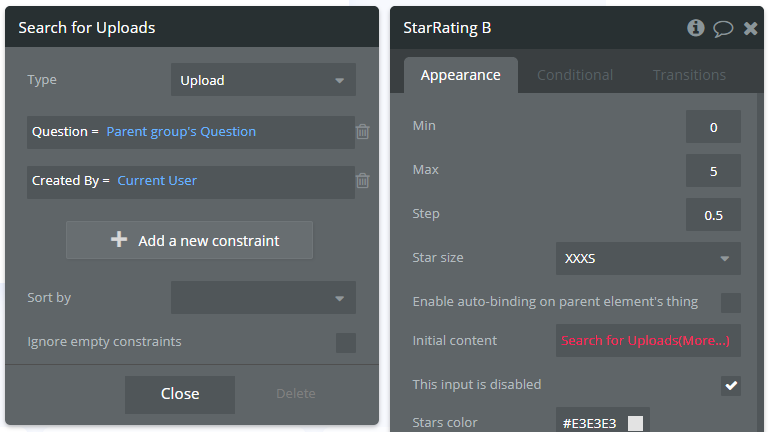
First I search for Reviews. Then I filter those Reviews so I only return Uploads by Current User and Parent Group’s Question.
I’m not sure why my “Upload = Search for Uploads(More…)” query isn’t complete (it shows in red). Shouldn’t this just return a list of Reviews that meet the Upload criteria?
Then, even if I got my Upload query fixed and returned a list of Reviews that met the Question and User criteria, how do I group this list of Reviews by Upload, calculate the average Score at the Upload level, and return the Upload with the highest average rating?
Didn’t quote your whole reply but lots of great info there. Thank you, Keith.
One thing about Things I’m still not sure about is related to the quoted text.
Bubble describes Things: “A thing, in Bubble, is an entry in the database. For instance, a specific car created by a user in our example.”
Let’s imagine a Car data type with fields Year, Make, Model.
The database entry: “2005, Honda, Accord” is clearly a Thing.
In an earlier post you stated “they mean a Thing (a custom data type). A field can of course be of type Thing.”
When you say “A field can of course be of type Thing” do you mean the field itself (e.g. Make), is a Thing in addition to the field data (e.g. Honda)?
Same thing with data types. Is the data type “Car” a Thing? Or are only the database records associated with Car (e.g. 2005, Honda, Accord) Things?
When you say “A Thing (capital t) is a custom data type created by the Bubble programmer user” it makes me think that both the Car data type, the Year field, and database entries such as “2005, Honda, Accord” are all Things.
But when you say “A Thing can only be created, modified, or deleted by the Bubble programmer user by explicitly calling the Create/Make Changes/Delete a Thing actions” it makes me believe that Car is not a Thing since it’s created via the Data tab, not the Create/Make Changes/Delete a Thing actions.
Rather than saying “A Thing (capital t) is a custom data type created by the Bubble programmer user” would it be more accurate to say “A Thing (capital t) is database entry associated with (a) a custom data type created by the Bubble programmer user or (b) the built-in User data type.”?
You’ve already been very generous with your time but could I trouble you to expound upon why I shouldn’t think in terms of rows?
I think we’re all familiar with Excel. What’s the problem with thinking about a Data Type as a an Excel tab, a Field as a column, and a Thing as a Row?
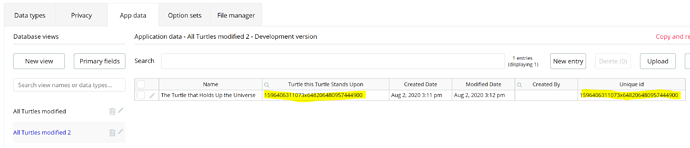
If you look at the screenshot of your Turtle example, this is how Bubble displays the data.
Turtles is the Data Type and is shown on it’s own App Data tab like an Excel tab. Fields are displayed as columns and the database entry is displayed as a row just as they would be presented in Excel.
I may not have explained myself properly, or probably didn’t understand your statement. You don’t need to duplicate any data. You just add the newly created thing. For example, create a new Thing of type Question. Then, add that Question to a list of Questions in Upload. So you don’t need to duplicate Question in Upload, just add the Question you already created to the list of Questions of Upload.
To give another example, let’s say you have a thing Post with an image and a description. Then you have a list called “Posts” (a list of Post) in a User. You create a new thing of type Post, and then add the newly created thing Post to the list of Posts of the User. There is no duplication: instead, you are just adding a reference to the new post in the list of the User’s posts. In other words, you don’t need to add an image and description to the User. That is already in in the Post. You just add the new Post itself to the User’s list of Posts.
You certainly could do both. Advantage is, as you say, you now have options for the query. Why you wouldn’t do both is: a) adds some complexity in that when you create or update records and connections you need to do it on both; and b) Bubble says that having too many listed (in the example, would be multiple Articles listed in the Author entry) is bad. From Bubble’s manual…
On your question about how to get your upload ranking to work, I don’t have any math in my app so I haven’t explored those aspects of Bubble. Without looking at the editor… my gut would tell me to create a repeating group that contains a list of the user’s uploads for a specific question (if you don’t want to display that list, you can make it hidden). One of the fields in that list would be an average of the reviews of each upload. Hopefully there is an average function that allows you to do it directly – otherwise can put another repeating group within that row (the 2nd RG would be a list of reviews for the upload) and take an average of that. Then sort the hidden repeating group by the averages. Then use a “first item” type of function to grab the highest one. (Again, all this is a pure guess – I haven’t tried any of this and surely there’d be a snag somewhere ranging from it doesn’t work, to it’s a bad approach, to it’s too slow).
If this is the issue holding you up, perhaps create a separate post on it and you may find someone who resolved the same issue. Also some of the experts that offer paid consulting may have an answer. Then you could figure out whether the answer is figuring out the query, or changing the data structure.