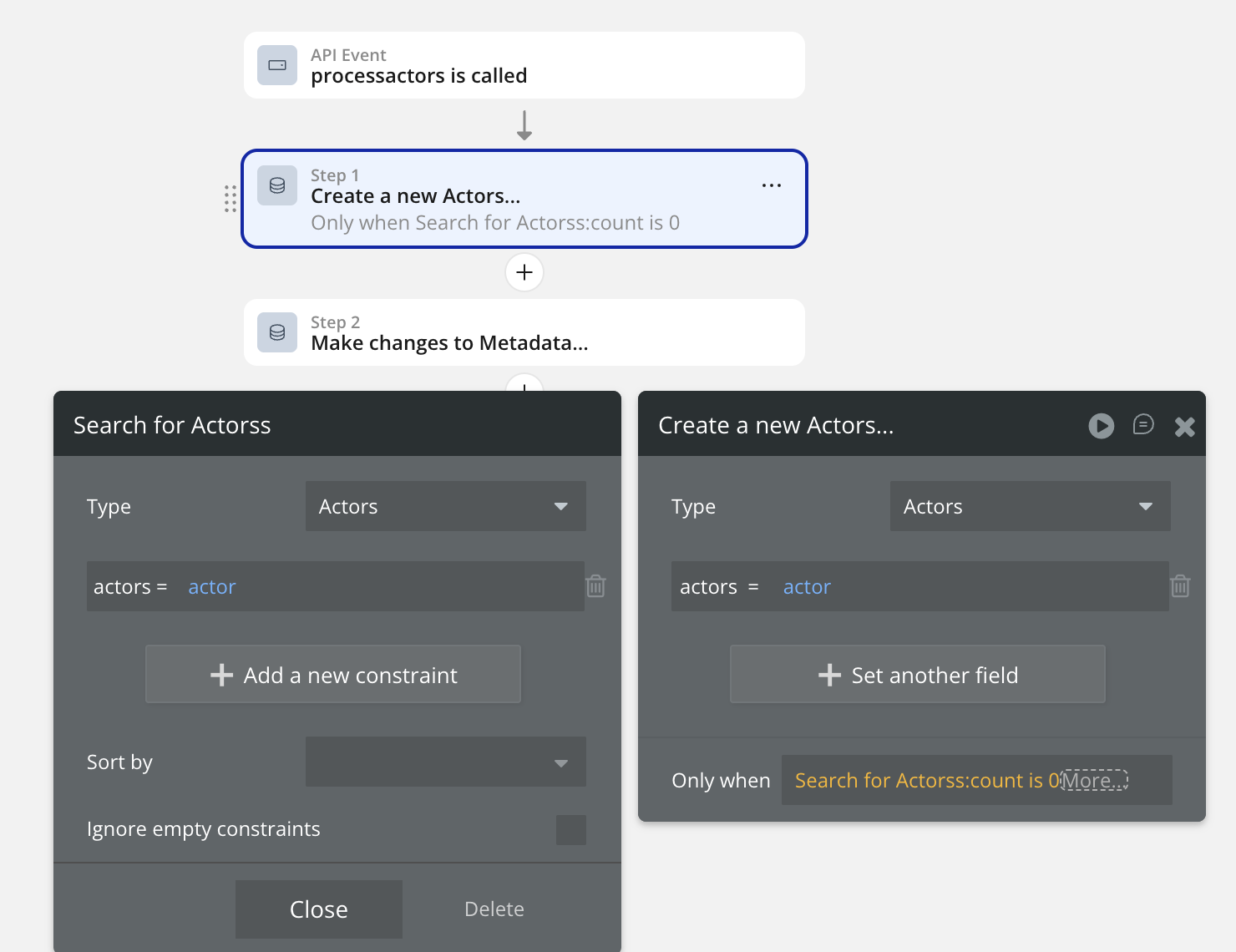
The workflow takes movie/TV metadata and splits the commonly used fields to make it more of a relational database.
I have a master table “Metadata” that contains everything and then various other tables like “Genres”, “Actors” etc. The workflow takes genres for example (list of text) “Action, Adventure, Drama”, looks for each one in the genres table, if its not there it adds it, and returns the object back to the Metadata table in the “Genre IDs” field.
The issue is i seem to have to run it at least twice for it to properly process all items. For example i would have 5 actors in the actors field, the first run it might only return 2 in the Actors ID field and the next run it generally processes the rest.
it is triggered by a button click and only runs on items not processed:
You are facing a racing issue probably. The problem is not the reliability of the backend WF but how you use it.
For example, if you are updating the metadaitem that link all the actors together, you may face issue when you use add because this all running at the same time, but Bubble may overwrite the value of the actors ID fields because of racing issue. You can add an interval of around 2sec to fix that
Had similar issues and, as Jici is pointing out, it’s a racing condition.
Some of multiple writes into one row of the ‘Metadata’ table in quick succession just get dropped although this isn’t reflected as an Error in the Bubble Logs.
You would have to process everything recursively and only write once to one table row in Metadata at the end of the workflow. It quickly get’s complicated when you have multiple branches / subprocesses to do that would have to ‘revert’ back to the initial workflow that triggered ‘processactors’, as you have to pass down all values that are needed in higher scoped workflows.
recursive_processactors (actors_textlist[list of text values for actors], actors_created: [list of Actors])
→ create actor (actors_textlist:first item)
→ schedule recursive_processactors(actors_textlist:minus actors_textlist:first item, actors_created+result of step 1) (if actors_textlist:count > 1)
→ Write to Metadata (if actors_textlist:count = 1)
100% agree on the race condition. A good solution here is a recursive workflow because you are running things in parallel that all update a single item when they complete. You will in effect publish a new list each time.
Either update with a Recursive workflow or change the DB set up.
If possible, you should avoid using recursive workflow. Shedule on a list is a lot faster and cheaper. In most case, you can just modify how it’s running to fix this issue or add interval
Just a note that the 2s change isn’t a guarantee. Might be ok in this case but if you were running this on something sensitive like payments, then you would want to set up a recursive flow so you can guarantee one process is complete.
Run workflow on a list IS faster, so if you change how you are saving things/referring back, this may be more efficient.
Not just faster… a lot cheaper. Can easily save 80-90% on WU.
Honestly, since Bubble fixed the issue with Schedule on a list, make it fast and allow more items, I’ve converted most of my recurring WF to it without any issue. The interval need to be calculated and you can also add some check to avoid error.
Also, you could consider reviewing your DB structure to fit your process. For example, in this case, I would just create the metadata with a list of text that would be the ID of actors. I could run all actors list in one Schedule on a list to create them and in parallel, Run the metadata flow to create all movies with the list of text of actors ID for this movie. This way, I don’t need to use “add” and will save on WU because I don’t need to update the metadata X times for each actors.
Agree with you. Would love to get an easy to implement solution for OP. Would you mind clarifying how you would change the DB schema and then the end process?
I think OP wants to know when the process is complete, and then return the IDs? Not clear actually on why they need the result.
But what I mean is not to store the Bubble unique ID of the actor item but the ID from the original source (I guess he is using an API but I may be wrong…)
We generally recommend an isLast parameter (yes/no), and scheduling API workflow on a list (this parameter’s expression is something like This Thing is List of Things to schedule on:last item)
The workflow will process in order, though, of course, still has race conditions. So, only when isLast = yes, schedule a workflow to run which does whatever you want to do when all the list is available. Whilst Bubble doesn’t technically guarantee that scheduled workflows run in order, you can be pretty sure of it in most cases, and it’ll run way faster than a recursive workflow. A recursive workflow is the only way to guarantee guarantee it.
Thanks for the suggestions, ill try explain a little more as to what i’m doing/why (i’m only an “intermediate” bubbler, lots trial and error getting to where i am!).
My “master” datatype is Metadata, i take our google sheet full of data and upload here (only the columns i need). when i first built the app i had 8000+ titles many fields - lets take genres as an example - my genres are all stored as a list of texts, so when i made an RG and a dropdown to filter by genre, the dropdown was very slow at loading as it has to check 8000 lists of texts and return the unique values.
then i learnt about relational databases and ways to do something similar in bubble. so i took all the columns of data that have common data (Genres, actors, directors, ratings etc) and made a table for each, the aim of the backend workflow was to iterate through each of these, add them to their respective tables if they don’t exist and then add back the unique ID to a new IDs field (List of Genreses for example).
So now in my dropdown i use the Genres datatype as the source, and on the RG i have a conditional when Genre dropdown is not empty > do a search for Metadatas > Genre IDs contains Genre dropdowns value. this all works great.
the problem is before this post i noticed inconsistencies in the data caused by the workflows, i thought i fixed the workflows, i deleted everything from the tables (Genres, actors etc) and re-ran the workflow on everything (bad mistake), i had to shut down the app because i noticed a huge spike and it used over 400k WUs… and all my attempts to stop it running didnt work (separate issue i contacted bubble about).
So i’m wondering, 1. is this setup with Metadata and the subtables a good/recommended setup? 2. if so, how do i convert all the list of texts to their respective tables and return the IDs without costing hundreds of thousands of WUs?
You could just use Excel as a simple way of creating the unique library of Genres and Actors, and then upload as CSV. At least for the initial bulk data set.
I understand the initial upload could be done manually, but the database is frequently updated with new titles. building something outside of bubble to handle this isn’t practical as that was the whole point of using bubble and its automation capability. just trying to figure out how others create a “relational” style database.
I simply want to improve performance and a relational setup seems to be the fastest when dealing with this much data (which i feel is only a modest amount). filtering the data (8000 titles) by the original genre field (text) is incredibly slow vs using genre IDs, so relational seems the only feasible way? but the automation process for taking a newly uploaded titles, checking if the genres/actors etc exist across their tables, adding new, then returning the ID to the main table seems costly on WU’s. unless my approach is wrong?