I’ve an API Connector that receive a response with 3000 items (it’s an 8 megabyte response). I don’t have any option to get a smaller response from this API.
I schedule an API Workflow on a list to create 3000 things (from the items received). But the API Stops creating things at ~321 ;
What was the raw response when you initiated the API in API connector?
Before you check this, please run the work flow in step by step mode and see the error
Even if I want to setup the recursive API Workflow to “Detect data” (I use CURL to initialize the datas), the API Workflow isn’t selectable when using an “Schedule API Workflow” … (you must choose “manual definition”).
But even the manual definition doesn’t have the “type” of the received data (body’s…)
Are you receiving the data via a GET, or is it arriving at an endpoint?
Can you say a bit more about the format of one of the items that makes up the overall package - ideally a screen grab of a sample payload from your API Connector?
What do you need to do with each item in the recurring workflow?
I’m receiving the data via a GET (an array of the datas bellow)
The format of one item: {"title":"abc", "id":123, "description":"lorem lipsum", ...}
I need to create one thing per item
This might be one solution:
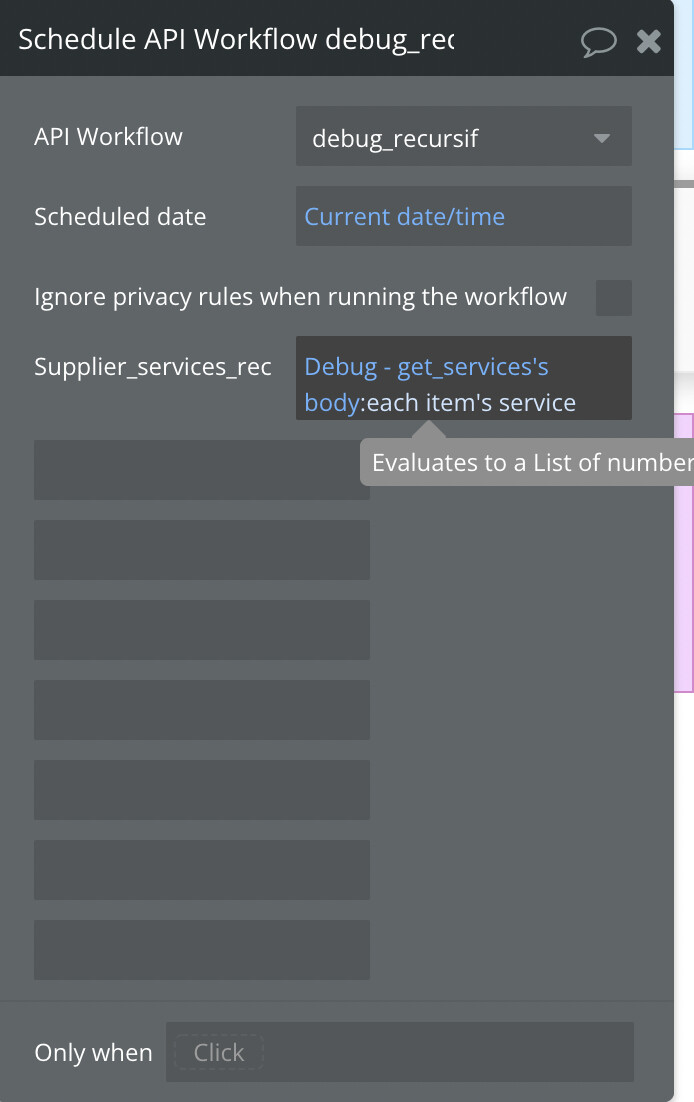
Setting the datas of the “recursive workflow” to arrays for each parameters ( title array, id array, description array, ... ). At least it’s accepted, I would need to iterate on the index.
It’s weird to split the object in multiple arrays of parameters, then using an index to rebuilt the object when creating “thing”, but it should work (testing now).
(array of the ‘service’ parameter built by using ‘each services’)
Yep, you can’t use API mappings as parameters for endpoints but you can use them as types in your database (in my example, a list of Google Sheets files).
So one quite clean way of handling this is creating a temporary table in your database which is a list of your api type type. Then, in your workflow, you create a new thing of that type, and set the list field to the response of your GET call. So you’ve now got your 3,000 responses in that single field.
You can now kick-off your recursive workflow, passing that Thing you created as the parameter. In your workflow you’ll create your new thing using the first item in the list then - before you recursively recall the workflow, you set the list field to itself, minus the first item in the list.
And of course you only recall the workflow if :count of the list is > 0
If you try what I suggest then let me know how you get on.
It’s what you were originally trying to do, but just using a database object as a vehicle to allow you to pass the list as part of the recursive call.
It should, and it’s a fact. Even if it’s still slow as f***, but it’s ‘normal’ as both methods are hacks.
The method I describe, which sends the full array (minus the created item) at each loop:
→ 1h31 minutes for 358 entries, it takes 15 seconds per thing (created)
Your method, which use a stored array in database column (removing 1 item on each loop):
→ 10 minutes for 109 entries, it takes 5 seconds per thing (created)
Theses times are very specific to this usage (an array of 3000 objects, that’s 8 mb in size), but it’s still interesting. Bubble could unlock a feature for this kind of situation…
V interesting. Great job for measuring and sharing back.
Last week I sent lots (~30,000 rows) from Node into Bubble via the API… the workflow checked for duplicates then created a new thing… then Node fired a new item back at the API every time it received a 200 response from the previous.
So, basically a recursive loop. It was averaging 1.5 seconds per entry… I guess the difference between the two is the iteration and movement of that big array.
Interesting to share, 1.5s is faster but wouldn’t be acceptable in my scenario. I’m very surprised that Bubble is still that slow in 2022. Calling an API which returns an 8 mb array shouldn’t be so complex / long. I came back to see what Bubble was capable of, but the “with-code” solutions (vs no-code) are evolving faster than Bubble.
So my learning of the past 2 weeks: In 2022 learning how to code is a better investment of time (vs learning Bubble)
I’ve created a small 3 lines code in AWS lambda to handle this, but it’s a shame for a no-code solution.