
Addresses gaps in bubble’s general capability for cloud file utilities that are apparent in issues such as [SOLVED] How to upload an image using POST API:
Critique of current bubble process ( binary file xfer )
File transfers require targeting and attachment of binaries directly in the body of FETCH POST operation that any browser supports. Any file in the filesys on the client AND any file publicly accessible via a URL transferred to any other API endpoint in a 2 step ( client piece , server-side ) process. Bubble currently does a poor job, attested to by forum activity on topics like Apis and binaries or uploading binaries.
Instead of a plugin, i built my own open components - client & server pieces with eye to HTML5 & node capabities ( streams , files , https ) that are easily adapted to bubble idiom.
Acting as a proxy, the server piece forwards any POSTED binary calling a 2nd POST ( dest = desired API ) with the uploaded request.body set to the request object ( binary file ) provided to the proxy.

Example function ( select a binary img from local fs and upload to a personal AWS S3 bucket ) . Response from server is JSON properties that can be passed into bubble.DB to record state of media files uploaded to AWS. If the AWS bucket is public then the DB url can be constructed from the response json.
I’ve seen zerocode’s plugin and its kinda complex re configuration. Although this approach uses native html tag and a seperate server process, its coded implementation is pretty simple…
select file to upload

post the selected file on http

server-side forwards to AWS Upload
with just small block of code that calls the AWS SDK details below

Once you transfer the client code from ( fiddle to bubble html native tag ) you have…
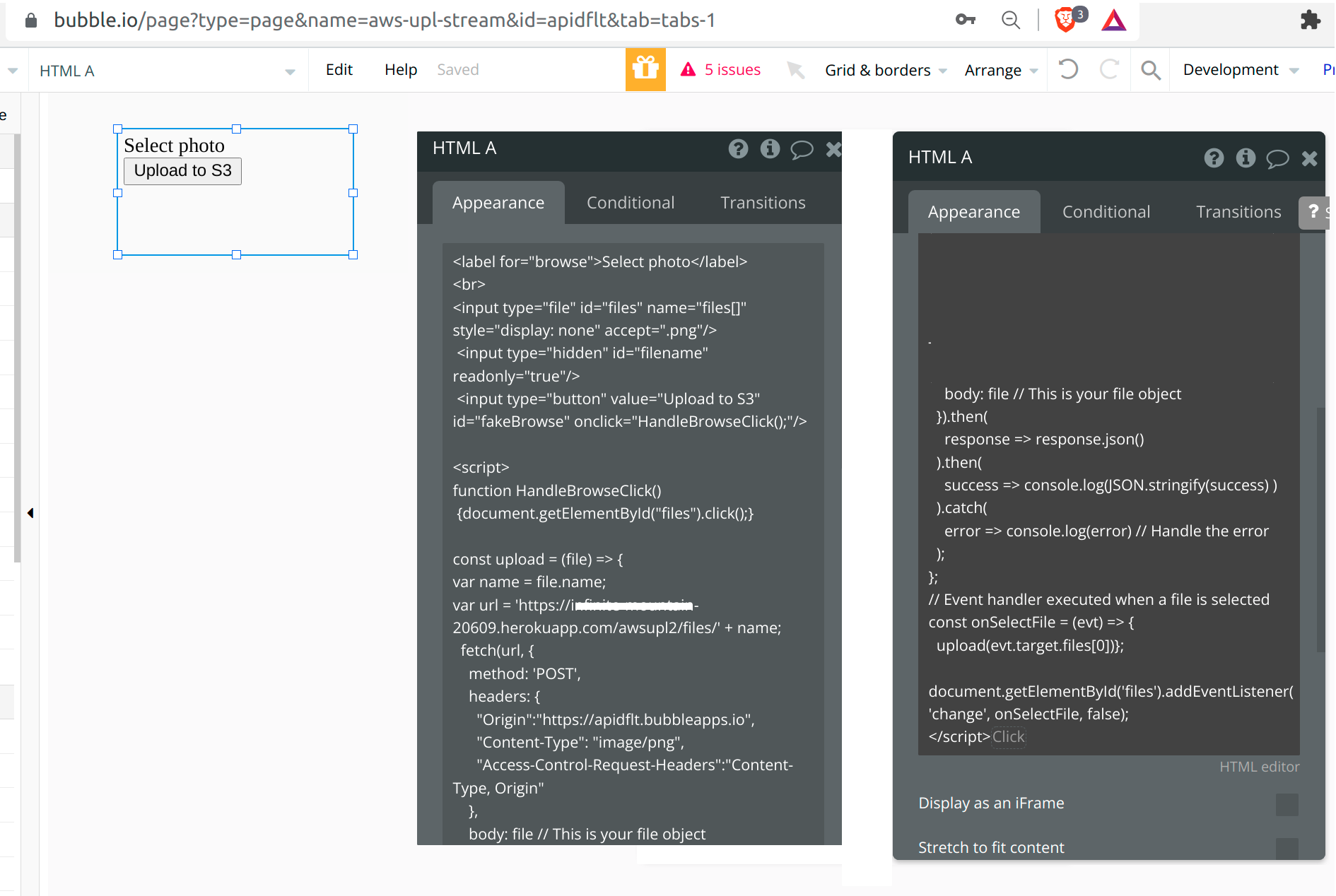
Running the bubble app with devtools, you have following after an upload to S3 bucket

free code ( fiddle for client, github for server ) . help yourself.
client - copy/paste from jsfiddle to native bubble html widget
server piece on github
General issues is the ease with which binary files can be moved around using mix of current tools ( native html block & node.express server ) permitting easy file handling , transfers among API endpoints.



