Just throwing my hat in the ring -
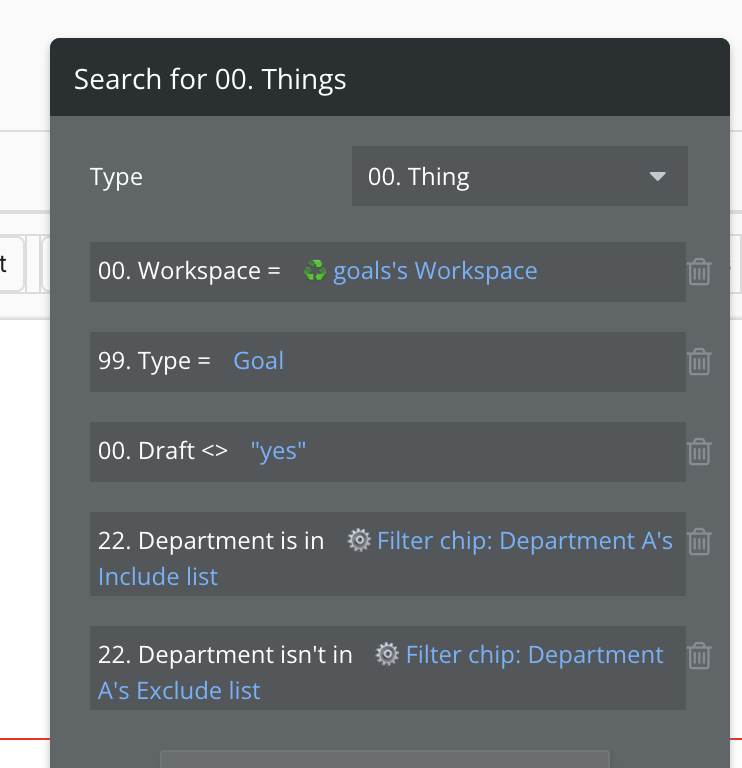
I found daisy chain filtering very useful for some more complex filter options, where I cannot check “ignore empty constraints”. For example I have a board of “items” which have a rich set of fields (primitives, records/“things”, and lists of things)
My primary filtered datasource on a “board” is a search for all items that belong to that board (people shouldn’t see things or be pulling item data from other boards… only items built in that board by themselves or collaborators). So this search cannot be thrown in with the filters on a datasource with an “ignore empty constraints” because it’s forseeable that someone could delete a board and then the orphaned items would suddenly appear. There are probably ways to work around this, but between my team’s imports, my DB management tasks, timed-out/errored-out workflows, and who knows what else, it’s not a setting I’m comfortable with.
I initially solved this with a
- Hidden RG Item with source search for items, where item’s board = this board
- Hidden RG Item-Filtered, with the user-selected filters that I can throw all together with “ignore empty constraints”
- The actual RG Item that renders the filtered data based on the selections.
However, I later wanted to give abilities to toggle filters that Bubble makes you work hard to get. For instance, if the user wants to filter by Item’s “Category”, they could do that - but what if they want to filter by “Category has not been assigned”? In the standard process, selecting (nothing) from the Category dropdown will just return all items. To solve this, I don’t find it advisable to default records to a dummy “not assigned” Category, but unless I’ve overlooked simple solutions, I don’t see really any solution except adding more and more convoluted filters to my NOT empty-contraint-ignoring Hidden RGs.
With Daisy Chain Filtering, I have a modular process to throw in these kinds of enhancements - each filter, as weird as it can get - is just another step in the daisy chain.
I also am happy with my current paradigm of using URL params with Daisy Chain Filtering. When a user applies a filter, my workflow simply sets the URL param via “go to page → current page”, and my Daisy Chain runs on Page Load. This is actually quite a lot cleaner than requiring me to build, on every filter dropdown change workflow, a custom state AND a trigger the “00-” step that kicks off the chain. I just set the param, and the page load flow takes care of it!
I’m curious if anyone thinks my method is bonkers or deeply flawed, but I’m much happier with this setup than the combined data source constraints. Works just as well, easier to maintain, and it unlocked quick enhancements that utilize URL history so people can go between pages and get back to their previously filtered view!