I use an external service to generate a PDF file and then I retrieve the original PDF file URL via API and save it to S3. The problem is that the original URL contains some extra arguments after the file name that should be removed before saving to S3.
Here is an example of the URL currently saved to Bubble S3
This is the screenshot of the backend workflow. When the Endpoint rpt_monkey is run, on step 1 action I call an API and I get the “document, download_url” info. This is the original URL with the extra parameters. Then, on step 2 I use the action …document_url:saved to S3. But the problem is that the extra parameters are part of the URL and I should be able to get rid of them.
The Amazon url parameters are always in a predictable order so you should be able to do a search for .pdf in your url that will give you a number of characters it’s found at. Then use :truncated to (that length+4) to chop the string off
Hi @richard10, I tried to implement your proposed solution but since the field where I save the PDF it is a “file” type it is not possible to do any truncate or search of any kind after the :saved to S3 action.
Just to better address the issue, one solution I can think of is to somehow remove the extra arguments from the original URL when saved to S3. But there should be also another option, like taking the file from original URL and save it with a custom name in Bubble.
Changing the original file name when saved to S3 should be a common option, but I really don’t know if there is a way of doing it. Anybody had this problem before ?
@ryanck I will write down in another post about PSD Monkey but I can tell you that their service is fantastic. After a number of disappointing, frustrating and time consuming experiences with all the well known Bubble PDF plugin client-side, I decided to give a try to PDF Monkey and it works like a charm. I can pass complex query via API, generate PDF without slowing down users and create nice looking templates.
There is only this stupid thing with Bubble that is not capable to strip the additional parameter coming from the PDF Monkey url. This does not mean that the file is not saved to S3 but just that when users preview the file they have hard times to download it.
I have asked to Bubble support too, but no useful insights from them. Talked to PDF Monkey as well and from their point of view the additional info in the URL are just there because the file is private and has a download expiration time. They say that Bubble should be able to understand the file name and separate it from the other parameters. Of course Bubble says that this is not how it works the saved to S3 action. And I got stuck in the middle.
I ma certainly available to pay for the solution, but I have not received any offer so far.
Once the file in S3 you can send it via email. The issue is only about the filename (I guess).
About the extra cost, my app is for managing business travel expense and the PDF is needed for accounting purposes. There is a free tier up to 300 PDF a month that I can use for my free users. Then I charge € 2.00 per expense report and I think that $0.09 per PDF is a reasonable cost that I can take. Of course if someone will ever make a Bubble PDF plugin working server side I will consider to switch.
Hi @lottemint.md, thank you for your suggestion. I took a look at what you are proposing and it is interesting what you have done in the test example. Maybe it’s me that I don’t understand, but the thing is that I need Bubble “save to S3” action point to the original URL (with all the extra info, since the file in PDF Monkey is private and the link expires after 30 sec) but then save the file with a custom name. This name can be extracted from the URL, can be taken from the API or I can create a name in Bubble. But what is needed is kind of “saved to S3” in two steps: first step tells Bubble the URL of the file to be saved and second step tells Bubble the name to give to that file. Any idea how to achieve this ? Many thanks.
Thank, @richard10 . Can you please make an example for me ? Because as far a I know Bubble does not allow you to put any other action after the “saved to S3”. And if you change the URL before the file can not be downloaded (since the extra arguments are for privacy and expiration).
OK
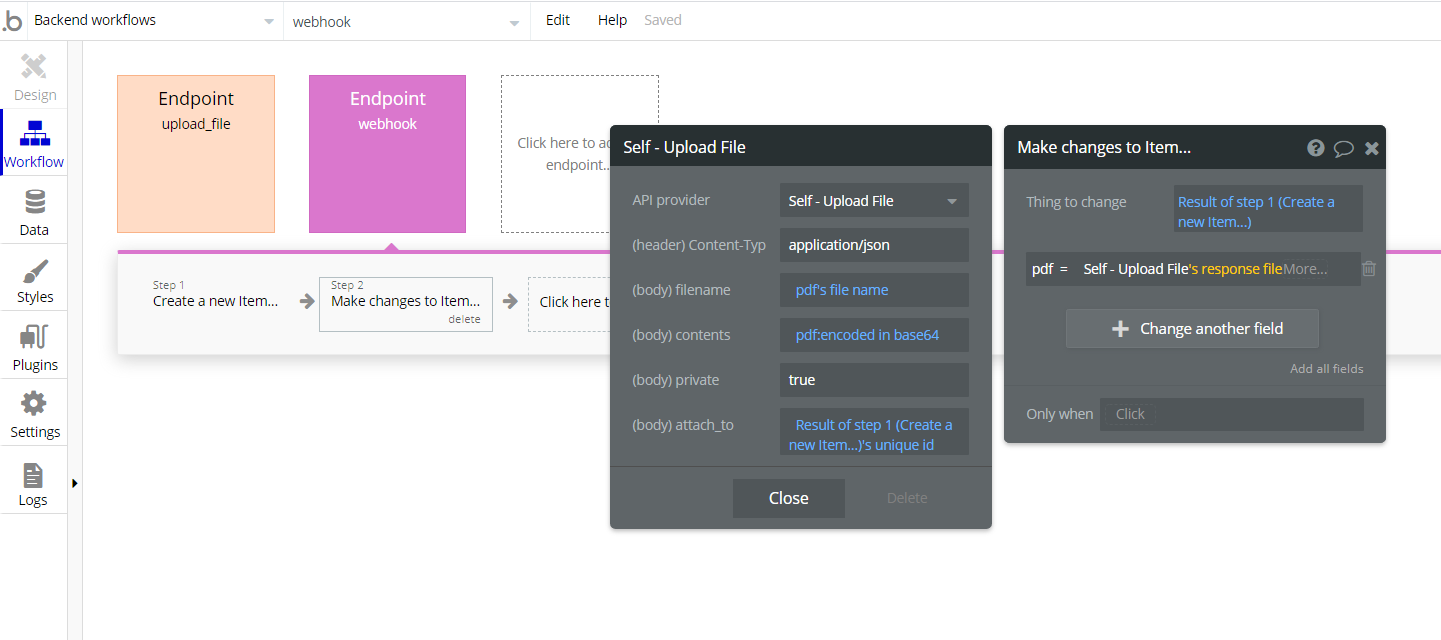
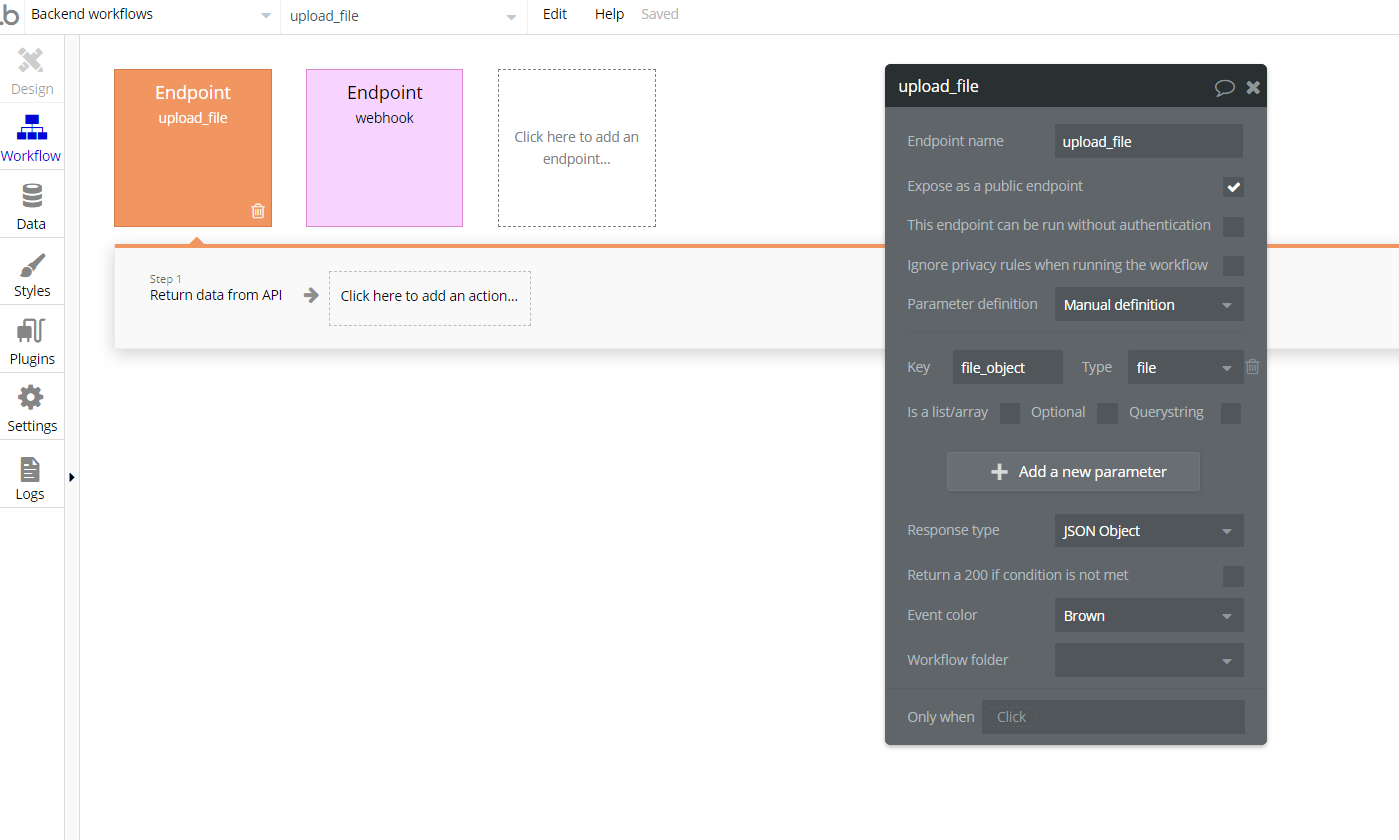
now I understand the issue, so ideally you want to
download_the.file%with%all%its%rubbish
then use that as a result of step 2
to
use_the.file:saved to s3
Right?
Yes, I need that Bubble let me point the original URL (with all the rubbish ) in order to download the file and then give me the option to change the file name before it is saved to S3.

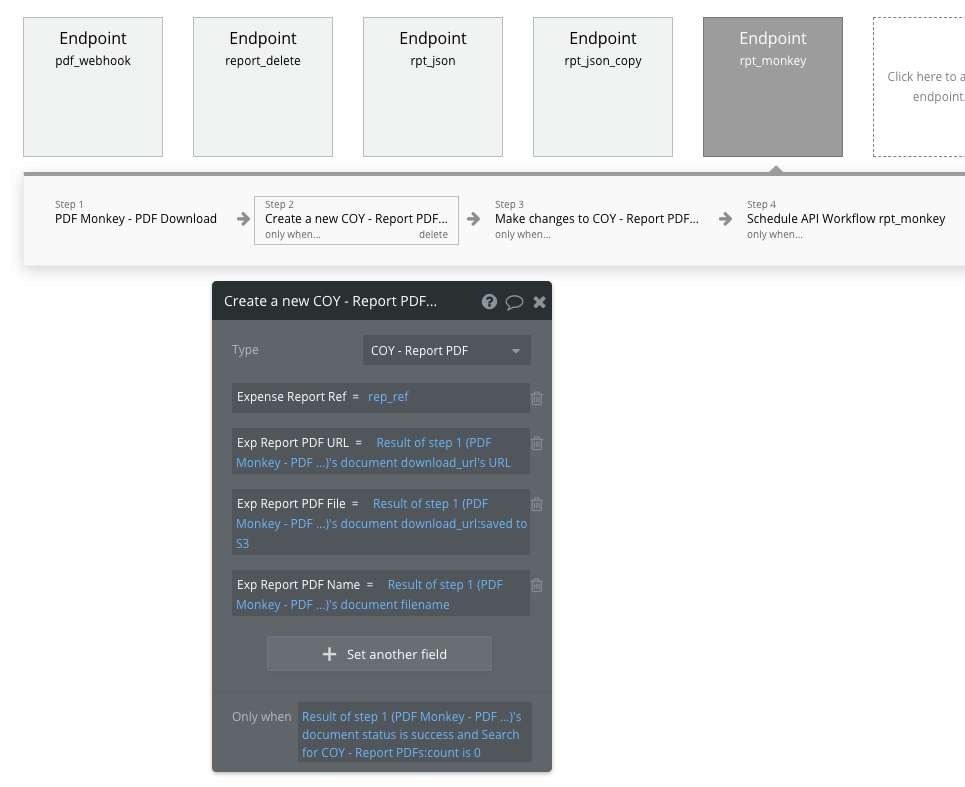


 ) in order to download the file and then give me the option to change the file name before it is saved to S3.
) in order to download the file and then give me the option to change the file name before it is saved to S3.