Within the backend workflow that I’ve exposed publicly I’m able to access the returned data as types such as response's body:first item's id. However, I need to loop over each item in body and perform some set of actions.
In the past, I’ve used recursive backend API workflows to handle looping over data, but in this case, I can’t pass a parameter of type response's body to a new API workflow and I can’t schedule a call to the public-facing endpoint in order to call it recursively.
How the heck are you supposed to loop over data like this? The response I’m getting could potentially contain thousands of entries, too, so writing everything to the database as temporary storage seems way too wasteful.
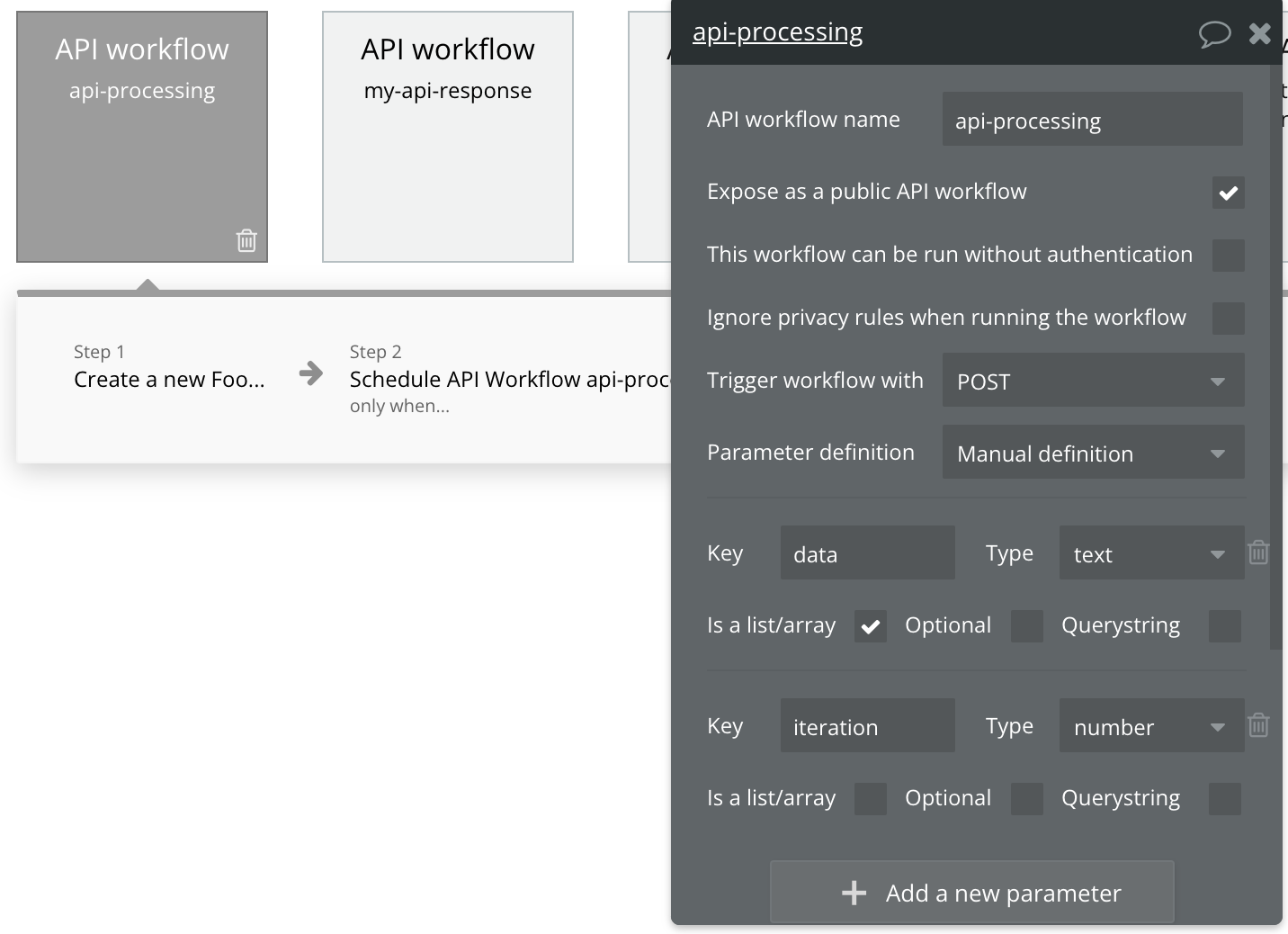
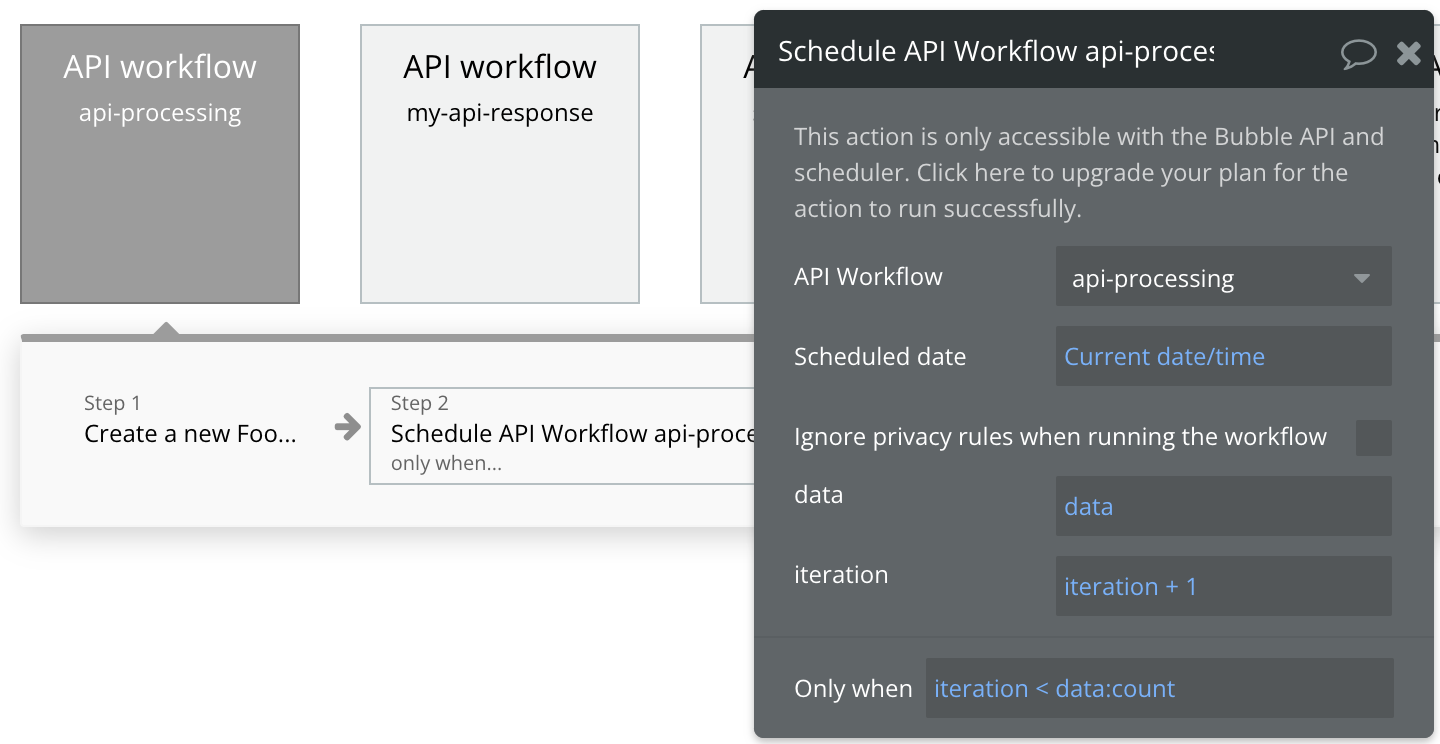
You would need to create one more workflow (internal/not publicly exposed) to accomplish this. In that WF create a two key-value pairs, one for dataset you are interested in processing with the Type of array (could be text), and another for iteration type of number.
In the WF actions “do any processing” by using iteration variable as item number, and call the same WF again in the last step by incrementing the iteration number by one. Add a condition so that this step executes when iteration < item array count.
@logicleapconsulting 's solution looks good, but is it scalable to thousands of list items?
@chris72 what kind of operations will the app do with the list?
Possibly you want a serverside action such as Toolbox server script, to run the data through a Node.js script and output aggregate data for the Bubble app?
If yes, you’d want to:
API endpoint: set to Automatically detect, and either grab the whole body as one Text, or turn on the “include raw body” option, to pass to the server script.
Or maybe just save the API endpoint’s data in the format it is received, save to database and loop through it on the front end?
Yes. I would make a change though to optimise for WU:
For the Schedule API workflow api-processing, just send the data. No need for iteration parameter.
In the api-processing workflow, create a new thing using data:first item
Schedule the api-processing workflow with data = data:minus item(data:first item) only when data:count > 1 (as when there’s only one data item left, we know that it’s all been processed)
We don’t need to send all of the data for things that have already been processed every time, so we can remove them from the list and forget about them.
What I’m trying to do is for each entry in the list:
Check to see if there’s an entry in the database that has a matching ID.
If yes, update the record. If no, create a new record.
The issue I’m running into when trying to do recursive looping is how to pass the data through. The source data I want to iterate over is an array of arbitrary objects. I haven’t found a way that I can create a backend API Workflow that accepts a matching data type without either storing it in the database or having it be an external API. If it’s an external API then I can’t schedule it, which means it can’t be recursive.
For now I’m going with “Schedule an API Workflow on a list” as an immediate solution, although I’m not hopeful about how that would handle a list with potentially thousands of items.
A little tweak to your option #2: " Write entries to the Bubble database in some sort of temp table and then process those entries since Bubble will then “know” about the data type."
If you only have ~100 entries coming in and 30k records in the DB, why not just create the 100 records as they come in?
Once they are in DB, you can loop thru them at your (really, Bubble’s) leisure, checking if they are duplicates or not (checking for unique slugs can eliminate WF heavy searches).
If a record is a duplicate, you can merge it into the original record or delete the original record (if that works in the data structure).
I did consider that. I was concerned about being 100% sure that Bubble is maintaining the order of each list so that item 1 in the ID list still lines up with item 1 in the names list, etc.
I would love to put them directly into the table itself, but I’m not sure how to do that without looping over the array of data I get from the API. Also, the fields that are returned by the API don’t match the fields for the Things I’m creating/updating, so I need a step where I translate.
@mishav, doing this all in a lambda function using the Data API is a different path I considered. One of our other developers has experienced rather annoying rate limits and timeouts when working with the Data API - timeouts that shouldn’t be happening according to the Bubble docs - so I wanted to try the Bubble workflow approach first.
We’re expecting that the vast majority of processes will need to work with < 100 entries, so the thousands scenario should be rare. If we start running into issues then I imagine I’ll have to revisit the lambda function approach.
It’s always nice when the best Bubble approach is “don’t do it in Bubble” .



 .
.