Hi Bubblers!!
I am new to Bubble and I have connected my application with the Assembly AI API. I have created a backend workflow that transcribes the audio and identify the speakers. It is everythink ok until here. My problem is: How do I display the conversation and the timestamps in the front end inside a text field separeted by Speaker? Example:
Speaker A - 00:00:00 - 00:02:19
text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text.
Speaker B - 00:02:20 0 00:03:32
text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text.
Speaker A - 00:03:03 - 00:04:12
text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text text.
.
.
.
Thank you guys in advance.
Generally the API call will return a list of objects, each object include a speaker and a text, so you need a repeating group to display that list and in each cell you can access the speaker and the text
1 Like
Hi, Salemmo! Thank you for your reply and help. I am just trying to figure out how to do that with Bubble. The entire transcribed text is saved in a field in my database. I had to use a kind of loop to identify the utterances (Assembly AI) and put each utterance in the Repeating Group but I don´t know how to call the utterances (speakers´s texts) from the API and display them.
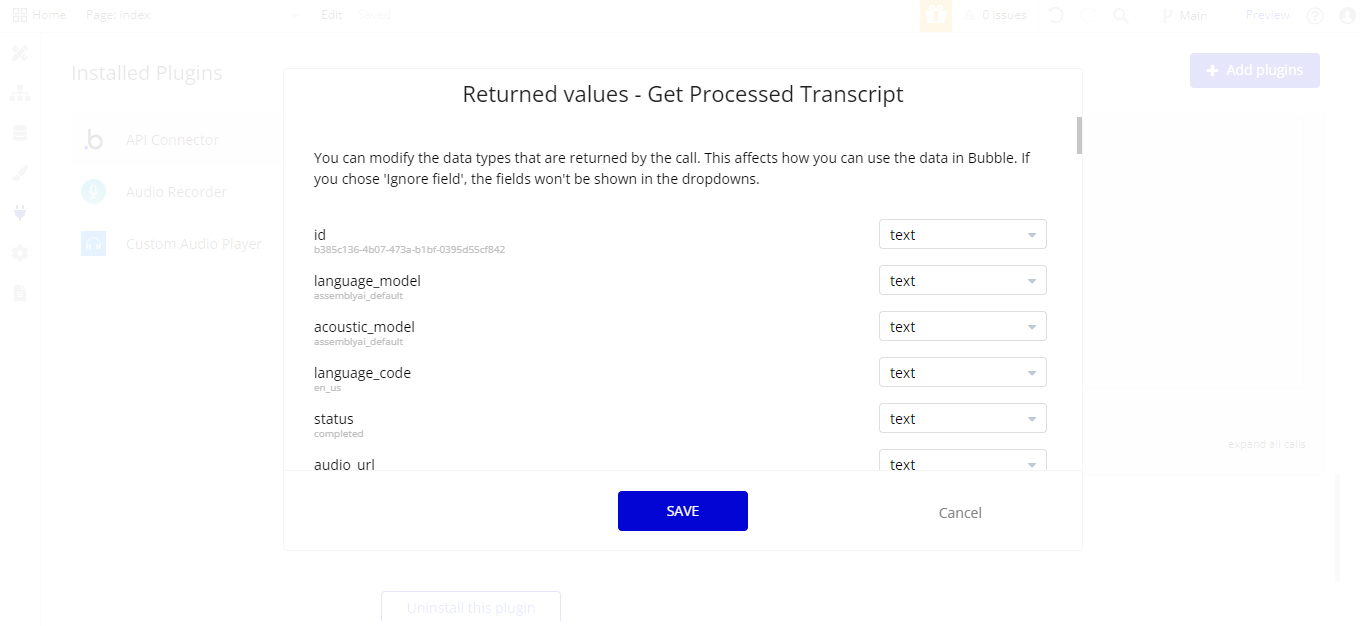
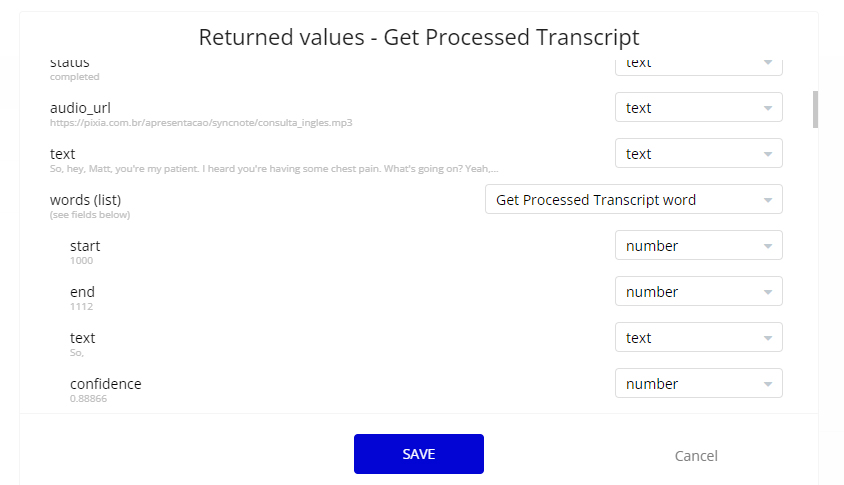
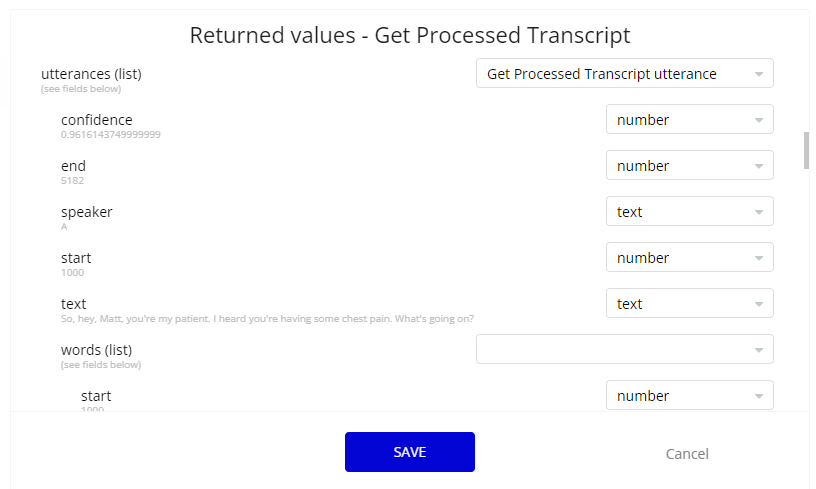
I need some screenshots for the response of the APU call and related datat types you made
1 Like
I can’t see information about the speakers, so you can’t achieve what you want using it, maybe there is a parameter you missed, or you may need to find another endpoint or another service that provides information about the speakers.
1 Like
Please, check if this helps.
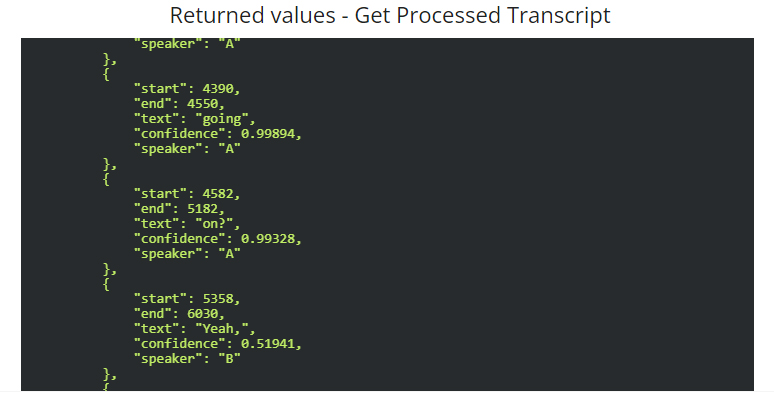
Yes this help, it seems that the screenshot number 3 is not correct, now you need to convert this list of words to a list of paragraphs, I don’t have a ready-made solution for this right away
1 Like
Ok, Salemmo! Thanks anyway!
I made an integration like this but for an app like Coursera so I made a plugin (Coursera text clickable sentences) that convert the list of words to list of sentences and paragraphs and the sentences are clickable and selcting text trigger workflow, but it doesn’t include handling the speakers because there is no need for this in my app.
1 Like

{kind=link}
{kind=link}
{kind=link}