
So I’ve been working on a project recently, attempting to create an interactive avatar with real-time features such as streaming audio with lip-sync data (phonemes) and support for vision to produce a digital representation of yourself (or some other character). I’ve come up with a demo that manages to do this. Because it also uses AI, it’s also capable of figuring out a specific facial emotion (48 of them in total) where one is chosen for every message you send and the face of the avatar temporarily changes to reflect that emotion whilst it’s speaking still.
This is mainly for use with AI applications where text to speech in involved.
It works relatively well in it’s current state, although there are a few tweaks I shall probably make within the coming weeks.
You can play with the demo here: avatar lip-sync demo
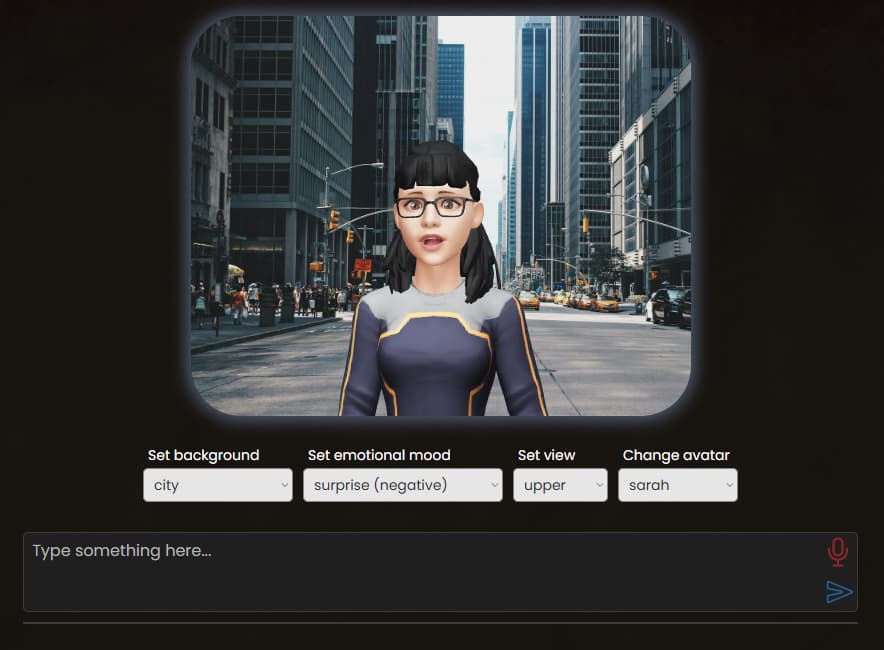
How it works…
It relies on a few things. You need to provide a GLB file (this is the avatar), a default one is included. The main library which runs this requires the GLB file to be based on the ReadyPlayerMe specs, as they contain additional data to help with the movements.
You can use any of these utilities to create a customized avatar.
There is only one text to speech service supported right now, and that’s cartesia because of their ability to produce phonemes (a language that represents units of sound) along with timestamps that refer to the timings associated to these sounds. These are needed to map the correct movement of mouth positions to the spoken text.
If enabling your camera, it will also be able to see you by analysing captured images.
Have a play, it’s not perfect but there’s room for improvement.
Here’s the editor if you’re interested:
paul-testing-1 | Bubble Editor
Paul