Sadly, despite what Bubble say, adding capacity (which is a paid-for feature, which makes it worrying) doesn’t allow your workflows to run any faster, or to have more of them.
Firstly, doing a “bulk” operation is really flawed in terms of capacity, and simply ticks over at 1 operation per second NO MATTER WHAT PLAN OR BOOST YOU ARE ON.
Suggest you avoid using bulk for anything more than a few items. It is pretty bugged as well on larger lists (I ran one for 10 hours last night and it did NOTHING).
A workaround is to create a recursive workflow, however, you need to be very careful here are there are significant bugs with the way data changes are picked up by the scheduler.
Secondly, adding capacity does not change how many workflows run per minute at all.
I hope Bubble sort this out, but in the meantime, I will be using Xano for anything remotely bulk data related. Which is really pretty sad.
That’s a helpful heads-up on bulk and capacity boost.
We’re processing quite large (and getting larger) datasets in the background. Speed not that crucial, but multiple threads of activity will be.
Most worrying thing that you mention for me are the bugs in scheduling recursive workflows (perhaps they apply to scheduling generally?). Could you share info on the behaviours that you have seen?
Likely something you’re already doing, but after reading the recent thread from Bubble on the mechanics behind backend workflows I have started including ghost parameters on recursive workflows / the reschedule call where that might help enforce concurrency. i.e. where it will help me create an unbroken chain of ‘Result of step x’… throughout the workflow, right up into the reschedule call.
Obviously only needed where synchronous execution is vital. Oftentimes asynchronous is preferable.
That’s rather disconcerting. And you verified that the field value was indeed not empty after the workflow ran?
I’ve actually had good success with recursive workflows. In fact, I built a batch processor based on recursive workflows, and it’s been working well. (I’m no longer involved with that project, so I can’t check to see if anything has changed recently.)
It was used primarily to export large data sets having complex relationships but also to create new Things based on data from other tables. It typically processed 50 - 100 entries per batch with 3-5 seconds in between batches.
One difference from your approach, however, is that I’m not using is empty as a condition. Since the batch processes had to be “reusable”, I created a Processed field of type date on the data types to be processed. That field is updated with the start time of the batch process when a Thing is processed. The data set is then filtered to include only items with a Processed time less than the running batch process’ start time.
The main issue with [complex] recursive workflows is that they can be quite difficult and tedious to troubleshoot.
The logs showed it updating the same field, with the same value, multiple times.
This is not just a test scenario, this is a real app, so further testing is going to be difficult for now.
Yes, that would be a good move. I have had to give up the “bulk” method and do it as each “chunk” gets manually migrated.
However, there is also another bug I have uncovered, in that if you delete the underlying “thing” in a field that has that as a type, it is no longer “empty”. It looks like it is null or deleted or something (it shows as deleted thing in the database view).
Given you now cannot either a) select empty rows b) select rows that have had something deleted you are pretty stuffed. But that is for another thread of bugs that I have uncovered while trying to migrate data into Bubble.
If I was doing any of this again today, I absolutely 100% would not use the Bubble database.
Bubble can handle a million rows if it puts them there itself. Upload 250,000 rows and then try to make changes to that data… it fails in so many ways.
Doing it in one-by-one in a workflow is entirely inefficent.
Given, at best, we get 1 workflow per second, updating 250,000 rows can take days.
So this really is the best way. Another part of the app is doing API calls and bulk data creation really really nicely. Works every time in “bulk” mode.
CREATION seems to be fine. UPDATES and worst of all DELETES in bulk are a horror story.
Sadly Bubble has known about the issues in the datatab forever, and seems in no hurry to fix anything now.
Thank you @NigelG and @sudsy for this excellent discussion, and concluding with “the best way” to do bulk operations within Bubble (without using external tools like Xano).
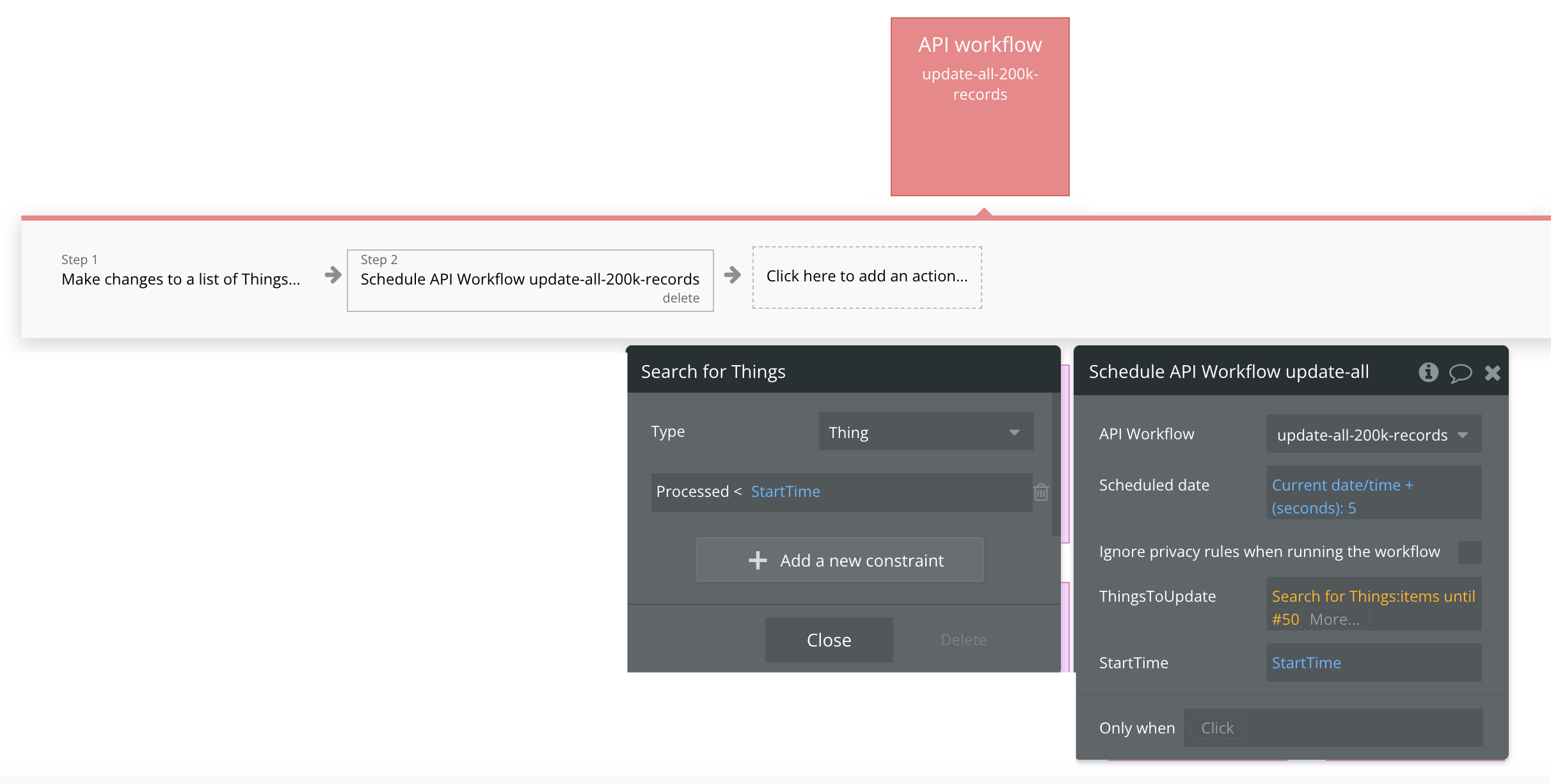
Would you please provide some additional details on how to build this “batch processor”? Suppose I need to update a yes/no field on all 200k records in my database.
If I understand your collective wisdom correctly, this recommended “batch processor” recursively uses the Make changes to a list of things...action (notMake changes to a thing...).
The recursive parameter for the Things is Do a search for: items until # 50-100 [below example uses 50] and a delay of 3-5 seconds [below example uses 5].
The search has a constraint (not a :filtered) to only include any Things older than the StartTime of the batch operation.