
If they do address this it would be cool if they could address case sensitivity search at the same time ![]() a checkbox that is just “ignore case” or something.
a checkbox that is just “ignore case” or something.
8 Likes
I’ll +1 that, and add my own: built in fuzzy!
3 Likes
Is that more performant than an advanced filter? I imagine it could be because the multiple searches all happen on the server, but curious if you did a test with some data from browser, as performance improvement should be significant enough to warrant increase in WU consumption.
It doesn’t bother or surprise me that Bubble is not the perfect tool for every problem.
I think we all know to use the right tool for the right job.![]()
The fun part is finding out everyone else’s tricks and tips. And having that “oooh I never thought of that - that’s clever” moment. ![]()
4 Likes
Best part of the forum. Learning new tricks, and having somebody else eyes pointing out a glaring obvious issue that your own could not see.
5 Likes
Okay, some more on the join table method, now I’ve done some proper testing:
To recap, this allows you search for Content that contains at least one selected tag. Here is the expression in a Repeating Group:

- if using this expression as is, Bubble will return ALL content, even if it is not visible in the repeating group, and even if you set a fixed number of rows in the RG.
- that results in Bubble doing a search once per second or so, until it finds all 15,000 Contents (even though it’s not showing them. So, don’t do that…
However, you can overcome this just by adding items until # for however many you want to load.

This has a clear limitation: it does not allow sorting. This expression is essentially saying, ‘find me 50 Contents by doing through the Content Tags, and stop when you hit 50’. If we try and sort the list before reducing to 50 items, then you have to go through all 15,000 Contents in order to know how to sort it.
So, does it work? Yeah, in a niche set of circumstances. Is it useful or scaleable, probably not.
And, it’s probably the same as an advanced filter for all intents and purposes, as it requires all Content Tags being loaded to the client, and then the Contents. From the Philippines (not sure to what extent latency affects total download time with Bubble) to download 18,131 Content Tags (to use as the unique ID is in filter for Contents), containing only the Content unique ID and the Tag unique ID, it took 21 seconds.
That’s two misses for me on this problem now. I’ll admit it’s beaten me and instead make myself at peace with the solution for the contains all selected tags solution using the Data API to add constraints programatically!
3 Likes
I don’t know if this breaks the rules or not.
In the tags data type create 3 fields, each is list of text that represent the Unique ID of the Content data type that has the tag. One field for the First 5K Content UID, one field for the Second 5K Content UID and one field for Third 5K Content UID.
On Content Type have a field that is a text that is not a list, but stores the tags as a single text with separated values (ie: tag1, tag2, tag3 etc.)
One page create an RG (hidden from users view) this will search for the Tags that have been selected by the User.

Then have another RG that is of type text that is the list of the UID of content from the RG for found Tags selected.

Then an RG for the Content that has at least one tag
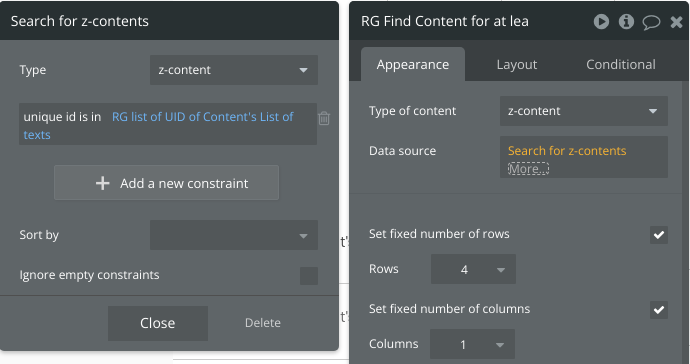
And then an RG for the content type with all selected tags
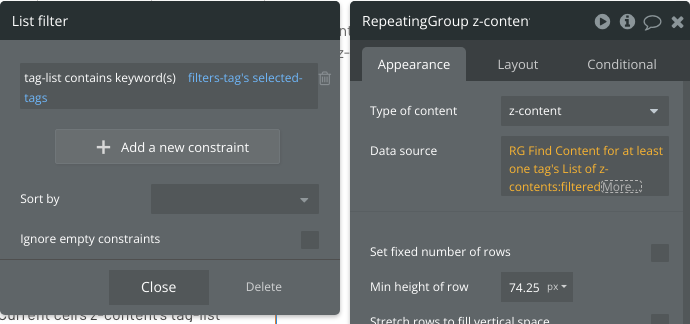


Performant and scalable…if you go beyond 15,000 content, add another field for 4th 5K content to the Tag content type.
1 Like
This is hacky but very creative ![]() I’m not sure it counts as scaleable if you have to add a new field for every n contents though
I’m not sure it counts as scaleable if you have to add a new field for every n contents though
Every 10,000 contents needs a new field.
So need 10 fields max…no need to add them later, can just do from the start.
That is the way to get the impossible done in Bubble, at least until they add the features we request that allows them to be done in a better way.
I’d say best part of this approach is that it requires just one search of the tags, which is already needed to show all selectable tags to the user. After that it another search for the content that is in the list of unique ids and then it is just referencing that first search of content and filtering off of it.
But alas, none of the solutions are going to work as well as they should…except for
One of the only two plugins I have purchased for apps and still actually use. I think I’ve only every bought 5 plugins.
3 Likes
That’s mighty impressive!
1 Like
Could be a testament to me being cheap or the vast number of very useful free plugins available.
3 Likes
Small idea to add to the discussion:
Could be easier with a RG for tags selectiong or with a plugin like selectize, but this can be done with Bubble multidropdown.
The solution is using a state “list of content”.
Tags need to also be stored in a text field
RG data source will be set to Search for content where tag contain keywords “selected tags”. :merged with state:unique elements
The first search will help to show most “relevant” items (that contains all selected tags). While the merge will be used to add all other items with 1 (or more) tags.
Add a WF that trigger on field change (or same idea if you use RG or selectize dropdown, with the correct event) and set state to add list of a search content that contain the last added tags to the dropdown (you will need to store and compare the state of the multidropdown each time the value change. This is why it’s easier with a RG or selectize that contain a state for last item added/removed)
I’ve not tested this solution. Just an idea that I got and want to share.
3 Likes
I may be missing something here, but I tried the Doesn’t Contain Keywords and it doesn’t seem to match on ANY tag as suggested.
I did something like this: concat_string_of_ids Doesn’t Contain Keyword(s) list_of_all_tags_minus_list_of_selected_tags
Is there something else to which you were referring to make this Match ANY logic work?
My testing shows that Bubble’s logic is that the constraint is effectively Doesn’t Contain All of the keywords I feed it. So everything matches.
Thanks!
I am playing with filtering and the “doesn’t contain keyword(s)” and the result is not what I am expecting, what am I not understanding?
I have a list of logs. These logs have a field note (type “text”). I want to filter the list of logs based on a list of text.

The list of logs is well filtered when there is only 1 text in the list of text.
The list of logs is not filtered at all when there is more than 1 text in the list of text.
![]()
![]()
![]()
@bonjour_17 I don’t believe that’s is a viable method for achieving this.
Indeed, it does not work. I worked my way around by using lists and intersections.
However, I am questionning my understanding of the “doesn’t contain keyword(s)” operator.
What is this supposed to do if not comparing a list of X against one X ?
Just discovered this thread, and I thought I’ll share what I know so far.
Have the same issue with a client’s app and instead of just one set of tags, the data has several sets of tags to be filtered by.
This particular app was for a set of places that can be filtered by various lists. Eg one is a list of categories, another is a list of closest train stations and so on. So far the there are 4 different sets of such “tag lists” that the user can filter by.
Similar to what @georgecollier stated, I planned to use a table of joins, that creates a new table of places and tags that the user can use “is in”. This result would then take only the unique items and display that.
So a place that has the following data:
| Place Name | Category | Station |
|---|---|---|
| Place A | Food, Nature | Station A, Station B |
| Place B | Entertainment | Station C, Station D |
Would result in a new table via a database trigger:
| Place Name | Category | Station |
|---|---|---|
| Place A | Food | Station A |
| Place A | Food | Station B |
| Place A | Nature | Station A |
| Place A | Nature | Station B |
| Place B | Entertainment | Station C |
| Place B | Entertainment | Station D |
Did not implement this since the client was planning on having more lists to filter by and it could get very messy. Plus maintaining the tags is a bit more work, if a tag is deleted or edited we would have to update the relevant records.
For the sake of the initial app, it was set to use the daisy chain filtering method, but as we all know that is not ideal.
Since then I have decided to use a different table. Instead of multiple columns for various tags, it would use one column. This would now have a new table of this format.
| Place Name | Search Text | Tag Type |
|---|---|---|
| Place A | Food | Category |
| Place A | Nature | Category |
| Place A | Station A | Station |
| Place A | Station B | Station |
| Place B | Entertainment | Category |
| Place B | Station C | Station |
| Place B | Station D | Station |
This method makes it easier to create new tags, though deleting one might be cumbersome. Plus I might have to use daisy chain filtering to filter from various multidropdowns based on their tag type. But no advanced filtering ofc.
Have not implemented this yet so will share my findings. If someone has already done this do let me know so I can save some time ![]()
Curious to know what your solutions were @adamhholmes!
There’s really no easy/efficient way to do this in Bubble - I’ve tested every single method in this thread, plus dozens more - and none of them are satisfactory - to the extent that I’d generally recommend NOT using Bubble’s database for this type of thing (as it’s fairly simple, and very efficient to do this with standard SQL).
But there are ways it can be done in Bubble, with some caveats, depending on the exact requirements - one of them being what you propose - i.e. using a separate table to link the content items to the tag - which is exactly how you’d do it with a standard SQL database (at least it’s one of the ways you’d do it).
So using a separate table for the content_tags is definitely a possibility - but in Bubble there are some issues that may make it not viable, depending on your requirements.
Firstly, using each item's content may be slightly faster, but will result in more data being loaded to the page (and therefore higher WU cost) than using Groupings - which are much more efficient (as only the grouped data is returned from the DB) - but either method can work.
And if all you need to do is load the list of items that contain ANY of the selected tags then this method works very well - it’s efficient, and fast.
But, there are a few issues…
Firstly, if you need to also display the Tags of each item, you’ll basically end up having to load the entire content_tag database to the page (which could be thousands or even millions), unless you also store the list of Tags on the content items - which is really the only way to do it, but it is redundant and shouldn’t be necessary (but it’s not a big deal).
But the bigger issue arises if/when you need to do any of the following:
- Display a count of the number of items
- Sort the items
- Apply additional filtering/search constraints
In order to do any of those things, the entire database of content_tags has to be loaded to the page (plus ALL matching content items) in order to sort/filter/count them.
Which is completely unscalable (and actually you’d be better of using an advanced filter- although that’s not viable either at scale).
The only way (in Bubble) to resolve this would be to include ALL of the necessary search/sort data on each of the content_tag items.
I haven’t actually tested that yet - but I can’t really see any issue with it, aside from the maintainability (and WU cost) of updating ALL related content_tags every time you make any changes to the content itself, so it might be a viable option.
But if you need to display the count of the filtered Items, then there’s no way to do that without loading ALL the content-tags to the page first in order to establish how many content items there are (whether you use each item’s content, or you use Grouping).
1 Like
I’ve recently become hooked on building ways to avoid searches or filtering happening within my apps, especially when it comes to large datasets that users are likely to want to filter or search through on a whim.
My approach is that if I can properly segment data by building more complex but strategically structured databases, in many cases you can avoid using do a search for way more than you’d expect.
@georgecollier ’s suggestion is similar to the path I would go down - essentially structuring the database in a way that allows categorisation of records to happen organically and before any searches or filtering has to take place.
I would structure something like this:
- Content (heavy dataset, eg 100k items)
- Tags (fixed / option set, eg 100 items)
- Tag Record
- TR Ref
When a user wants to add a tag to content, instead of just listing the tag against the content, we create a Tag Record.
The Tag Records are then stored under a TR Ref, and the TR Refs are essentially representative of each tag (ie there should be exactly as many TR Refs in the database as there are Tags).
The TR Refs act as a way to collate all instances of an individual tags uses, and all corresponding content items which the tag has been added to.
Note, we could store the Tag Records against the Tag, but if they are option sets / for big datasets I would avoid this
With the multi dropdown, when the user selects a tag / tags, we then display a Repeating Group with the data type / set up that looks something like this:
Type of content: Content
Data source:
Multidropdown tags value: each items TR Refs Tag Records: each items content
(Essentially saying show me all content items that have had the selected tag applied to them).
If you didn’t want to load each items content, you could also have the type of content as TR Refs, and then filter down the TR Refs based on the multi drop-downs value. This is probably where I’d be most creative with filters to keep reducing that total number of records.
What this means though is that instead of searching through 100k records to find content that has the tag applied to it though, we’re displaying a corresponding list of all exact instances of when the tag has been applied to content.
If there’s an average of 3-5 tags per content item (random assumption, but for the sake of the discussion), we’re reducing the records to search through by 95%. Again, what we actually display in terms of the content or the TR Ref is where you could be creative to continue optimising.
I would also be inclined to use this approach if the other important areas that were mentioned (data insights / counts / etc) were a high priority. This is because you don’t have to apply a count after a search, you just apply a count to the TR Refs Tag Records.
I prefer this approach of data categorisation in many cases because of the additional utility you get from creating a record rather than simply logging a data type against another / as a list of records.
This is also just my initial response to how I’d approach it (written out through the notes section of my phone not with practical examples) so apologies if I’ve overlooked any part of it.
@adamhholmes I’m intrigued as to what the quantitative indicators of success would be with this challenge from your point of view, ie if we had 100k records but only had to perform a search on 3% of them to achieve the desired result, would that constitute a success?
1 Like