
Not Quite Unicorns Style Guide & Development Philosophy
This guide details an approach to building Bubble apps followed by Not Quite Unicorns, the youngest Gold tier Bubble agency.
A version of this exists on a Google doc which you may find more readable: Not Quite Unicorns Style Guide & Development Philosophy - Google Docs
This guide may be updated, but the forum restricts edits after a while, so you can use the Google Doc as the source of truth.
Background
Not Quite Unicorns (NQU) specialises in saving apps from other freelancers, agencies, and citizen developers. Clients come to us when they hit a wall with their app, have bad experiences with agencies, or have built themselves into a hole and need expertise to get out of it.
As a consequence, we very often see how not to build a Bubble app - more often than we see how to build a Bubble app.
Our business model is a productised service. We do not bill hourly - we bill by task. That means that as an agency, our goals when building are to:
- Build in a maintainable way
- A maintainable way means a way that makes it easy to revisit, re-use, or modify a feature, without having to tear it up entirely
- If we take shortcuts, we shoot ourselves in the foot, because it’ll take longer to iterate on down the line, when our client is still working with us
- Build things the best way, not just a working way
- Virtually every problem in Bubble has multiple solutions. It is up to us as developers to first know what those solutions are, and then evaluate the best one.
- Never be satisfied with “good enough”, and you’ll thank yourself in the long run.
- Build for the needs of tomorrow, rather than the needs of today
- Linking the two above points, everything we build must be built with the client’s future in mind.
- We do not build features in isolation. Features are designed to solve core business problems - it is solving these problems that we optimise for.
- Therefore, even if the immediate requirements of a feature are fairly small and simple, we should build it in a way that supports simple future development.
We’ve done pretty well for ourselves by following these principles. The average Gold tier Bubble agency is over 5 years old. NQU is just over 18-months old at time of writing. We achieve this by retaining clients and showing them that we deliver good value. We are not the most expensive option on the market. Therefore, our gains almost exclusively come from an obsessive focus on building things in a maintainable way that makes it easy to change them in the future.
So, we are speaking from a place where we’ve proven that how we build works - on both clean apps, and when saving tech-debted apps.
What this guide is and is not
This guide is not intended to be:
- A bible of the only, correct way to build things on Bubble
- A claim that no better approaches exist than the ones we suggest
- A course on Bubble basics or an exhaustive list of best practices
Rather, this guide is intended to be:
- A proven, documented approach to building apps
- Food for thought to develop your own best practices
- A system on how to think about building on Bubble
This is not a best practice guide. This is a good practice guide - if you follow the principles and systems in this guide, you will likely end up with a good app. This is because the principles and systems we speak about here encourage you to think about Bubble in a certain way.
This guide is also opinionated and to the point. We think it’s the best way to build a Bubble app, but every app, agency, and client is different, so you may find some parts irrelevant or counterproductive for your own development style. We will make generalised recommendations, but there are always edge cases.
Let’s begin!
Naming conventions
Throughout your app, it is essential that at a glance, you can tell what you are looking at, and what type of data you are dealing with. If you’re familiar with TypeScript, this is the kind of feature you get in an IDE - it is easy to know whether you’re dealing with a text, a number, an object, or else.
It is important to accomplish the same in Bubble.
Elements
Sometimes, no naming convention is simplest.
Now, it may sound absurd opening a build guide with such a statement. However, I will explain the rationale behind it.
Bubble has, implicitly, instilled a universal naming convention upon us for front-end elements. You know this when you place an element on a page. It will default to Text X, Group Y or Button Z, for example.
I do not see any value whatsoever in naming every element. There’s value for you as a developer if you’re paid hourly, but it does not deliver value to you as a developer, other developers that might work on the project, or your client. There might be a claim that it helps with readability, but I think that’s very limited, and if you do modify element prefixes for readability, you likely don’t do that for every element (and therefore aren’t disagreeing with my core argument that we do not need to rename everything).
Examples of naming conventions for every element which hold little semantic or other value include:
- Prefixing all groups with GR_[group name]
- Adding emojis into names
- Removing the element type entirely
Now, there are a few reasons why:
- Most groups are functionally irrelevant and serve no ends other than being a way to structure the UI
- Using a specific, complex naming convention makes it harder for a developer unfamiliar with your project to begin working on it
- It can make search more difficult, as when most developers are used to searching for
Button [x], if you’ve renamed all buttons toBTN - [x], it takes away that muscle memory.
Now, there are some things which I think should be named.
As a rule of thumb, if the element has a workflow or some relevant logic, it should be named so that it is clear what it does. That means that, for example, almost all Buttons should be named e.g ‘Button Create Account’ or ‘Button Make Payment’.
Additionally, key UI elements/groups should be named usefully. For example, you may name the header ‘Group header’ or a card ‘Group user card’. However, it generally makes sense to keep the prefix (the element type) as-is, so that other developers know what they’re looking at.
Custom states and group variables
Against custom states
We do not recommend using custom states at all. There are a few reasons for this:
- They are functionally inferior to group variables, as they cannot be set dynamically in an elegant way
- They are not as visible as group variables in the editor
In almost all cases, anything a custom state can do, a hidden variable can do better. One notable exception is passing data between reusables.
In defence of group variables
A group variable refers to making a group or repeating group have a data source. That is not to display anything, but is to store a dynamic variable that you can later reference. For example, if you reference an ‘Invoice’ in multiple places on the page, it makes sense that all references to said invoice use the group variable.
We recommend naming group variables as var - [name]. This makes them easily searchable and distinct in your scan flow. It doesn’t necessarily have to be var exactly - VAR might look cleaner to you, and that’s okay. It should, however, be short end easily searchable. var is convenient to type with one hand on the keyboard.
- Group variables are highly visible and can be dynamically set
- Group variables can be placed globally (e.g. in a hidden floating group), or locally (next to where they are used)
Storing hidden variables in a popup or floating group is functionally identical with the caveat that plugin elements generally do not load in a popup, so it would be advantageous to use a floating group. That said, I’m normally in the habit of using a popup which is fine for most use cases, so you do you.
Let’s unpack what I mean by placing a group variable globally or locally.
Suppose we have an invoice page, where we display the invoice’s line items, and also some customer details. The customer details are collapsed by default.
In a popup, we would have a hidden variable var - Invoice. This references the invoice we’re displaying, and would often come from a reusable element data source or property. Also in the popup, we would have var - Line Items which is a repeating group that stores the line items to display. The search constraint would be Do a search for Line Items where Invoice = var - Invoice’s Invoice.
These are global variables that dictate the entirety of what the user sees, hence they’re positioned in a hidden popup where they can all be viewed and managed together.
Now, let’s consider the case where we want to monitor the expanded state of the customer details. I may have a hidden variable right next to the customer details card, called var - customer details expanded. Why? Locating the hidden variable geographically close to where it is used/updated can assist understanding its functionality. You can judge which location for the particular hidden variable is right for you.
Naming pages and reusable elements
I do not have any particular system that I think is best for naming pages and reusable elements. As long as they’re named consistently, it is likely valid.
Take this page manager screenshot from NQU Secure:
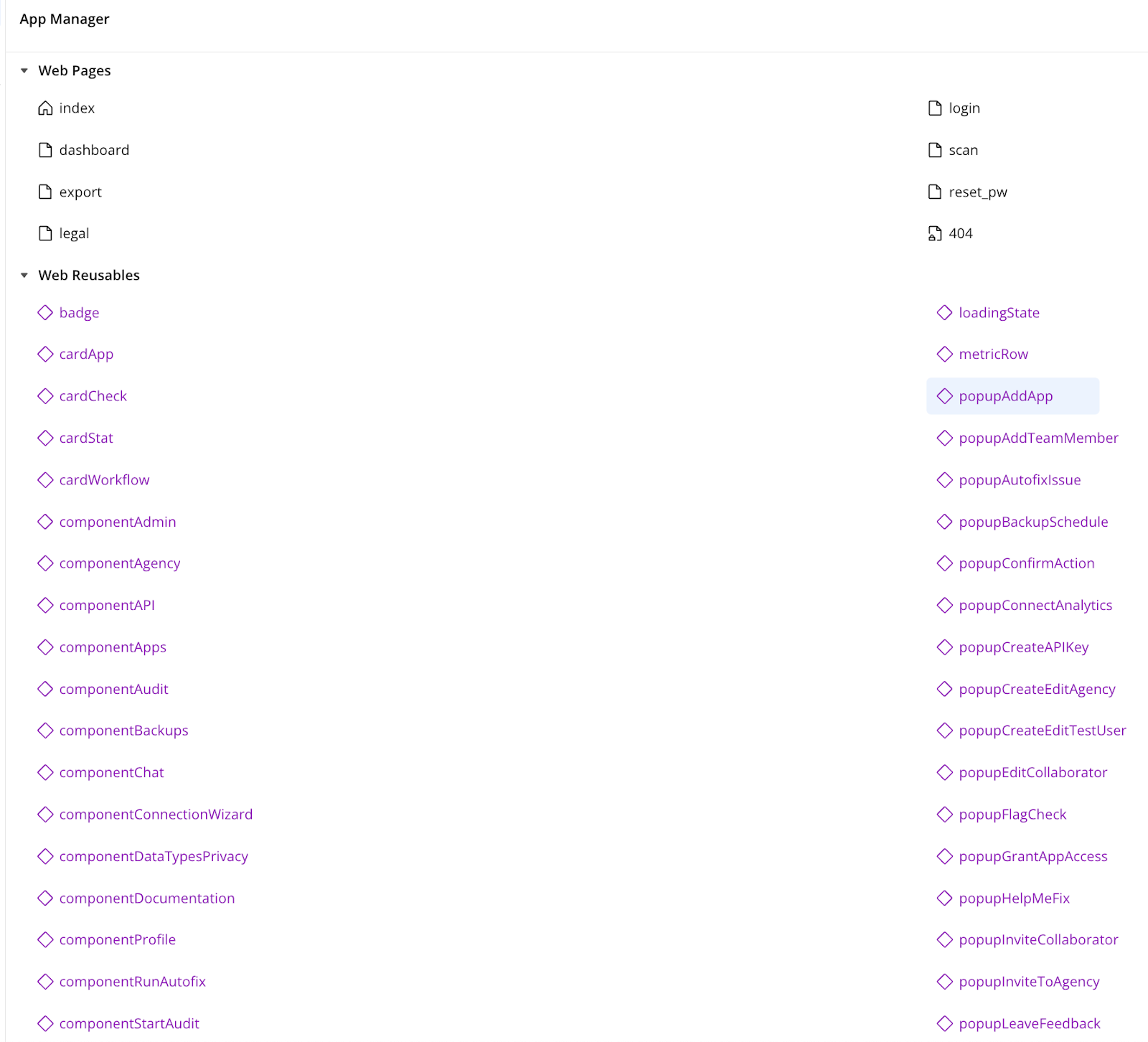
You will observe a view things:
- All popups are prefixed with popup. This makes it easy to find any popup. Additionally, all popups in this app are reusable elements. I think every app should use this practice. More on that later.
- Specific UI components like cards are named as such e.g cardCheck, cardApp
- Non-specific components like componentAdmin and componentApps which show the admin panel and the user’s apps respectively, are prefixed with component, for lack of better options. I do not currently have a better approach to recommend here but will update the guide if I find one.
Data structures, workflows, and calling a spade a spade
Now, naming elements is only part of the app. Based on my experience, the naming convention (or lack of one) of front-end elements doesn’t affect the maintainability and readability of the app too much.
It is in the logic and your data structures that naming conventions do become non-negotiable.
The naming convention I will show you is based on the following principles. Names must:
- Communicate what it is for
- Communicate what type it is
- Be easily readable and plain English (or whatever language you develop in)
- Do not overcomplicate - call a spade a spade.
So, here is what I recommend:
Data types, option sets, fields, and attributes
All data types and option sets should be in Title Case and singular.
| Good examples | Bad examples |
|---|---|
| Invoice | DT_Invoice |
| Invitation | user_invitation |
| User Role | OS - User Role |
| Product | ProductID |
| Billing Account | stripeBillingAccount |
Some people will claim there ought to be a distinction between data types and option sets e.g with a prefix. I do not find this convincing. It will almost certainly be self-evident given the app context whether the type you are dealing with is an option set or data type. If there are two similarly named data types/option sets, then yes, clarify that in the naming of them.
So, this clarifies naming for data types and option sets themselves.
Whenever we reference a type (i.e, another data type or option set) in a field or attribute, we use that type name exactly.
When we reference a basic data (e.g date, text, number), we use camelCase with no spaces.
This is best demonstrated with a screenshot (this particular one is the Check data type in NQU Secure):
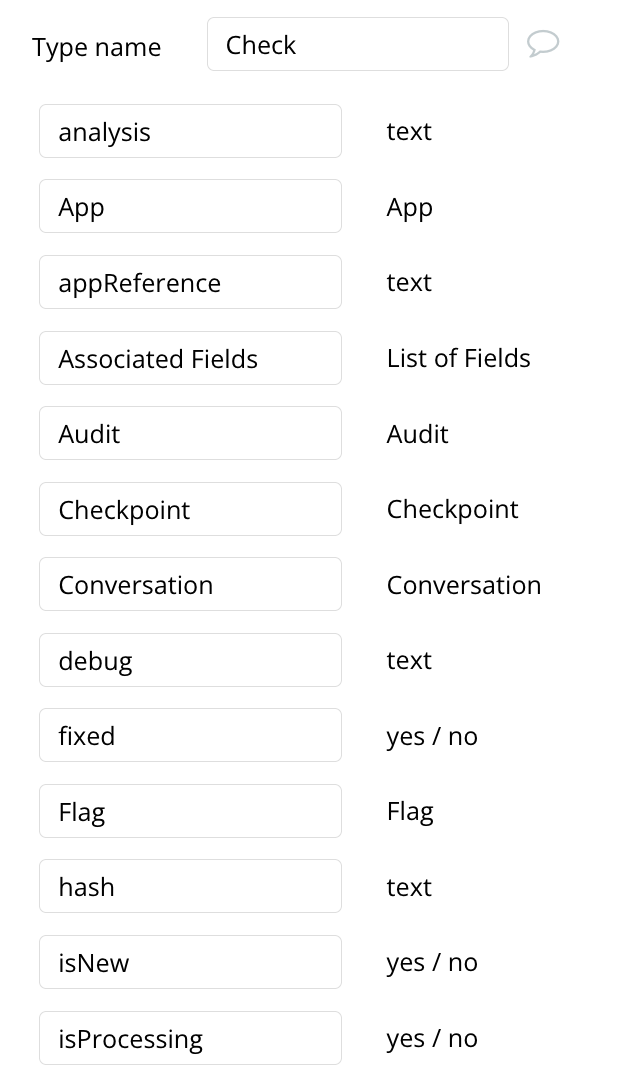
Now, a few observations:
- All basic data types are camelCase
- All links to other data types are Title Case matching the name of the type we are linking to
- There is an exception which is Associated Fields. Often, it is necessary and beneficial to add more clarity as to what a field is used for. For instance, in NQU Secure, we have a list of Verified Apps and Pending App (both lists of App data type).
- Booleans (yes/no) are generally prefixed with isX.This is because it is readable, and makes linguistic sense in a Bubble expression (e.g This Check’s isNew)
Workflows and logic
The real power of this convention comes in workflows.
We title all workflow parameters in the same way. Our approach heavily uses custom events, backend workflows, and reusable element properties. That means passing data between functions frequently.
Let’s take a look at this custom event:
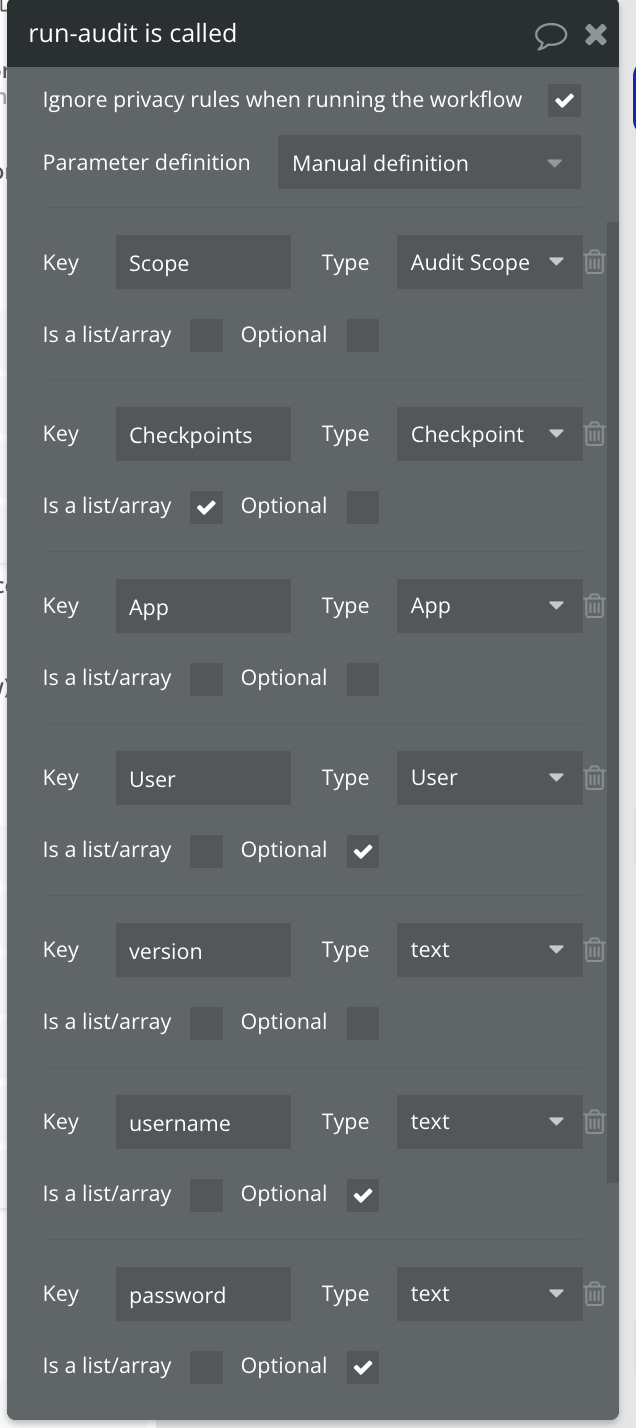
You can see that wherever possible, we name it exactly the name of the type of data we are dealing with.
Inside the workflow, this makes it extremely easy to know what type of data we’re dealing with. Of course, when editing expressions, Bubble indicates to you what kind of data you’re dealing with, but by naming in this way, you get a much quicker intuition for how the workflow works and what it does.
So, let’s look at how that’s applied:
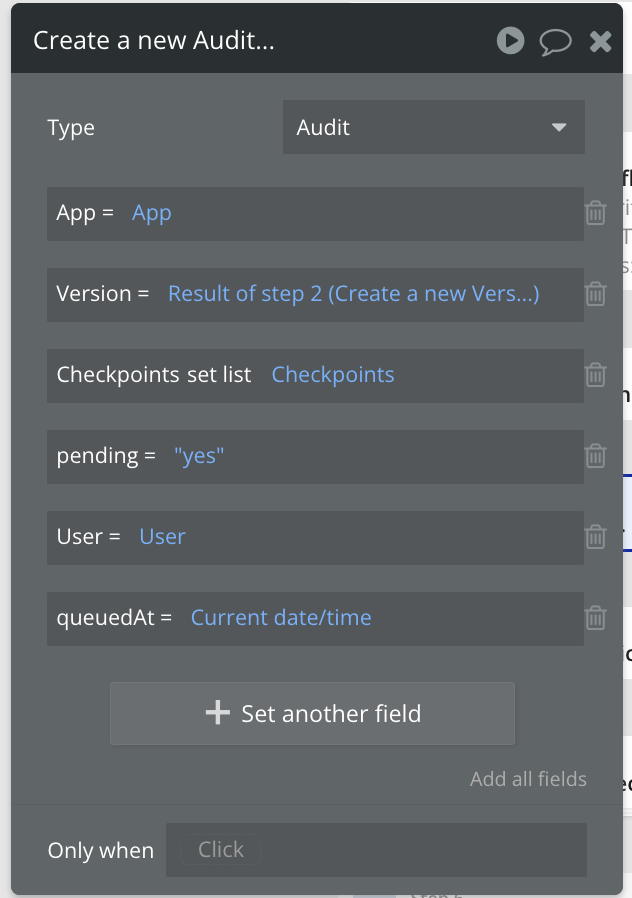
Would you look at that! It is intuitive which inputs map to which fields, because of our naming convention. User = User, App = App, and call a spade a spade.
The purpose and type of each field is clear, and it links to our database intuitively.
Data types and option sets are Title Case - they look big. They are proper nouns!
Basic fields are camelCase. They are, well, basic, and simple.
Backend workflows and custom events
Much like naming reusables, I don’t have as many hard and fast rules with respect to the naming of backend workflows and custom events. Personally, I go for Title Case. I used to do kebab-case-like-this, but reflected on it - what’s the point? I want names to be readable, not technical. To me, Complete Audit Processing seems much more readable than complete-audit-processing. In addition, going back to this ‘proper noun’ idea, it gives the custom event/backend workflow a bit of weight. Perhaps that sounds strange to you - I don’t know if other people feel the same way. That’s why I’m sharing it!
Security
Privacy rules should be applied as soon as a data type is created (or as soon as practical)
Applying privacy rules immediately ensures that you structure your database in a way that supports privacy rules. In addition, adding them later leaves a lot of room for bugs to creep in, as bugs relating to privacy rules can be hard to track and debug.
Privacy rules are the only thing, without exception, that protect data read access. You must configure them, and they should be the first thing you do as soon as you create a database structure.
Backend workflows should be public if and only if necessary
Public backend workflows are fairly easily exploitable from a security standpoint. They used to be public by default, but fortunately Bubble has recently patched this.
Go through your app and ensure that only backend workflows that need to be public are public. A backend workflow only needs to be public if it’s being called via the API.
This might be, for example, for a webhook that’s received from Stripe, or an API that you call internally via the API connector.
Anything that lives on the page is accessible to a client
This isn’t so much a best practice as it is an FYI, but anything that you put in a workflow or on a page, on any page, regardless of whether it’s protected by a redirect or not, is publicly accessible. Do not statically define API keys in plugin elements on the page or in workflows.
Remember that any text, for example, AI system prompts that live in a reusable element or a page, are going to be exposed.
You should move it to the backend if you do not want it to be exposed.
Workload
Excessive focus on workload hurts clients and maintainability
This issue frustrates me so much. I see some developers investing so much time and effort trying to squeeze every last workload unit out of their project. However, I don’t think this is beneficial for the app, the developer, or the client.
Do things in the right way, in a way that makes things easy to change in the future. It is not worth spending $100 of development time to save a client $1 a month in workload units. Only optimise workload issues when they become an issue.
This does not mean it is acceptable to not use best practices with regard to workload. It just means not going above and beyond to make the primary focus of your development be reducing workload costs. If you build in a way that makes things easy to change, then it won’t be a problem to easily optimize in the future if necessary.
Take a marketplace which shows a list of products. This will consume workload units when someone loads the homepage.
If the client starts getting 50,000 views a day, then the costs of such search will likely start being significant, so it might make sense to refactor that into a satellite datatype to save the workload. But this should happen if and only if the workload savings are worth more than the development time plus any maintainability cost associated with the change.
External databases should not be used with Bubble*
Following on from the above, no app that is entirely built on an external database should be built on Bubble from the start. Bubble is a full stack platform. It is a bad front end and it is a bad back end. It is a fantastic full stack developer experience.
If your project requires an external database, it should not be built on Bubble. Bubble is a bad front end and is clunky to integrate with external back ends. You are better off using a tool like WeWeb, which is purpose built for this use case and is objectively a better front end.
If you try and sell a client a new Bubble app with an external backend, you are not selling them the best option. You are selling them an option which is convenient. Bubble is where your knowledge lies. You are failing the client by not recommending them that better option.
In existing apps, there may be cases where a small number of tables may benefit from being in an external database. However, this is rare and should only be done as a last resort.
This should only be done if the cost-benefit analysis, when factoring all in, including the cost of the external database, the cost of the additional development time to implement it, and the cost of maintainability, indicate that this is the best option for the client.
Satellite data types should be used sparingly
Satellite data types add complexity and maintainability challenges to the app. There are occasionally good uses for them, but use them very sparingly, particularly when the only reason for their use is workload savings.
If it provides significant performance savings in terms of speed, then that’s a more convincing reason to use it.
For example, in a recent app, we had a file data type which stores files the user uploads to chat with an AI. Originally, we stored the content of the file on this data type, but that obviously meant that when we used the file browser that we built, all of the content for each file had to be downloaded to use that.
When we saw the sizes of the files that people were uploading, we moved the content to a separate file content data type, rather than being on a content text field. This way, we only need to load the file content when we want to.
Modularity
Don’t pass data between multiple parent groups
A common setup in a repeating group, for example, a repeating group of tasks, is to have the cell and then in its child cell reference parent group thing, and in that child cell reference parent group thing, etc. This is a pain.
If you want to change the type of the repeating group for the purpose of copying it to another part of the UI, or just a change in data structure, you have to update every single group’s type and reference.
Instead, in a repeating group, the top-level group should be a group variable, which is the thing for this cell. Then all references to that thing inside the cell should reference that hidden variable rather than the parent group.
Here is an example of a good pattern:
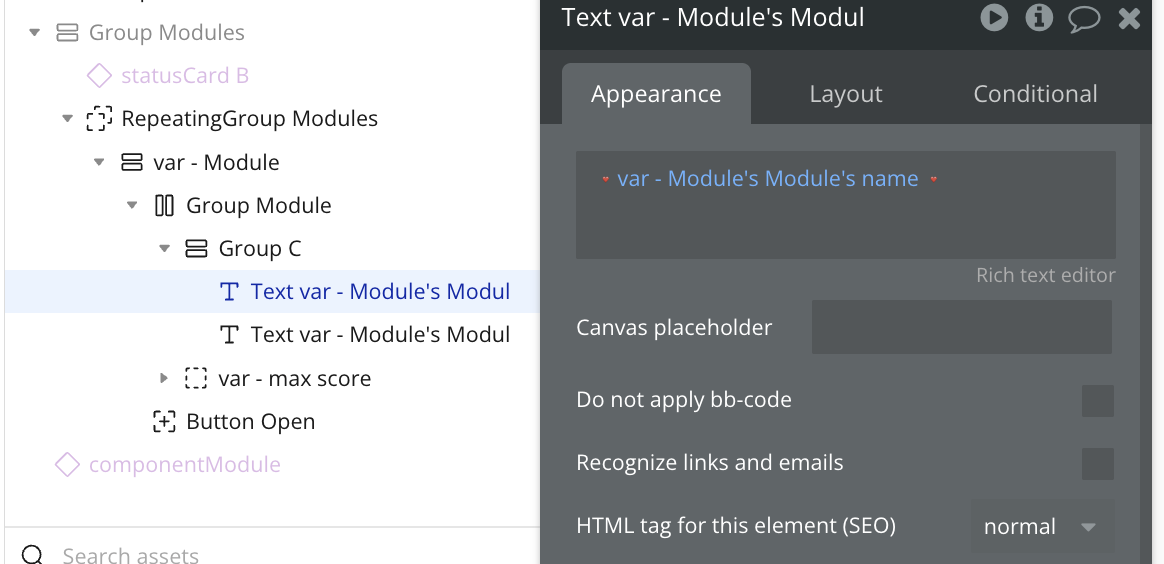
The only common exception is when the parent group data is required for auto-binding.
The default ‘Creator’ field should never be used
The default creator field is a pain and really causes trouble for us when we take on apps. The challenge here is that you cannot manually assign or override it.
For example, if we receive a webhook or we call an internal API with an admin API token, then the creator field will be the admin rather than the user. This limits how much we can build in the backend and makes it near impossible to reassign data to a different user.
For example, if we have a project management tool where a task has an owner which is a user, bad apps will use the creator field to say who owns it, because that’s who created it. However, it should have an owner user field that can be manually changed.
Privacy rules, etc., should always reference this manual field rather than the default creator field.
Essentially, pretend the creator field doesn’t even exist.
All popups should be reusable elements
All popups should be reusable elements. Each popup should have a custom event to open and a custom event to close. Closing the popup simply hides it.
Opening the popup uses the custom event to take any parameters that the popup requires or can optionally take. It then displays those inside hidden variables inside the popup as desired. Then it shows the popup.
The reasoning for this is simple. It means you can just drop a popup on any page. You can trigger the popup using trigger custom event from a reusable element workflow action. This custom event will contain all of the parameters that you can provide to the popup. As a developer, this means you know exactly what it takes and how it works so that whenever you place it on a page, it will just work.
We recommend against using data sources of popups and instead take the data from the custom event that opens it. The reason for this is that it’s easy to forget to assign a data source.
By having all data that a popup requires pass through a custom event when it’s opened, it’s clear to a developer exactly what this popup needs or can take as an input.
The additional setup is minimal, and the maintainability gains are enormous.
Think about reusable element scope and responsibility
One pattern that I see in apps is a reusable element for all, for example, delete actions. This popup will take a bunch of different data sources, of which only one is ever used, and will delete it. For example, this one delete popup might handle deletions for invoices, payments, chats, profiles, etc. The reason this happens is because the developer sees all of these functions as being related by virtue of them being delete actions. Therefore, they can be put into a reusable element.
However, I do not think this approach is particularly elegant. I find this diagram useful:
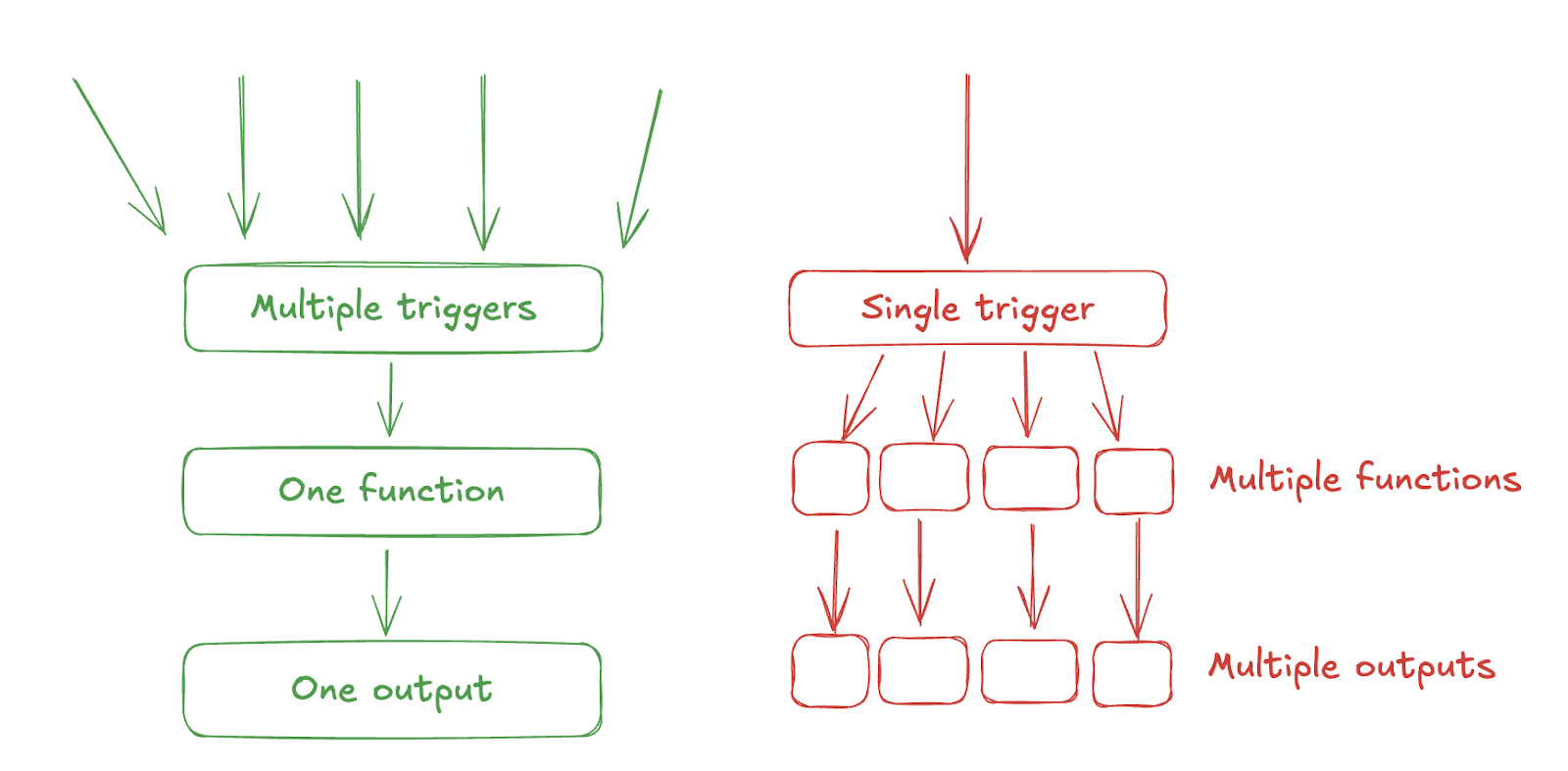
Essentially, everything that we build should take one set of inputs and return one set of outputs. This is known in code as the single responsibility principle. It means that we always know what something takes and what something does.
Everything in the app is in small reusable components. The delete pattern I described above is based on the first example. There are multiple functions inside the popup, and the response is different in every use case because there are different delete workflows for each thing.
The approach that I would recommend for this deletion example is associating all of these actions, not by the fact that they are deletion actions, but that they are confirming something. To that end, I would have a confirm action popup. This popup has reusable element properties for the title and description.
Inside the popup, when it is confirmed, or if it is confirmed, we set a state on the popup which says confirmed is yes. Whenever we want to use this popup, we place it on the page.
Let’s say that we want to use this popup. Suppose we’re on a profile and we want to delete the profile. We click the delete button, trigger this confirmation popup, and then we have a listener on the page.
Do when this popup’s confirmed is yes. When it’s confirmed, we run our deletion logic. Now, someone might initially say that that means that the logic is on the page so we can’t reuse it. That’s correct, which is why it’s wise to put it into a backend workflow so that it is reusable across the app.
Geography in your app
In addition, keeping the delete logic geographically close in your app to where it is used, such as in the profile itself, rather than in a dissociated popup, means it is easier to semantically understand how your app works.
I’m not sure how much this concept of geography is intuitive to other people or if it’s just something that I picked up. But I do feel that it makes sense to keep logic close to where it is used. The same principle applies in traditional code.
Reusable element properties and custom events are your friend
Reusable element properties and returning data from custom events were single-handedly the best features that Bubble added for maintainability since the responsive engine. They are now significant proper use of modular functions.
Each reusable element and custom event can have its defined narrow purpose so that each component only does one thing and does that very well. Now that we can return data from custom events, it is easy to have reusable logic that lives in a global reusable element or directly on the page.
Make extensive use of the backend
Lean towards using backend workflows as it makes the app so much more maintainable. Backend workflows should be clearly organized into folders. You may have a preferred naming convention for backend workflows, which additionally assists with organization.
Every app should have backend workflows for actions like signing up a user. This workflow runs and takes a user parameter, which is their created account. This might be used to create data things and tie them to the account or send emails, etc.
Every app should also have a send email backend workflow which takes the content, the person to send it to, the subject, etc. This way, all of your email logic passes through one place. Should you change provider or change the API call, you only need to update it in one place.
People see the backend as a downside because it’s asynchronous, but that’s okay. Most things can be asynchronous.
The backend is pretty fast, and generally when you schedule something, it will generally run immediately.
Closing thoughts
I hope that offers some food for thought. As I mentioned in the beginning, every app agency and developer is different. This is just a system that we’ve proven to work on well-built apps and poorly built apps that have been handed to us.
There are edge cases for everything, so a rule of thumb is never a black and white rule. Hopefully, there is at least one thing that you can take away from this that you find useful.


