I’m hitting performance and workflow-unit limits when running searches over my entire “Data Type” collection. I’m exploring best practices for handling very large datasets (thousands of records) in Bubble. ChatGPT suggested using a backend workflow—specifically “Schedule API workflow on a list”—instead of client-side searches, but I’m struggling with the setup.
What’s the recommended way to configure and invoke Bubble’s “Schedule API workflow on a list” for bulk processing without blowing through my unit quota?
Any guidance or examples would be greatly appreciated. Thanks!
ChatGPT is probably wrong. You should consider better filtering, pagination, db structure as way to reduce WU. I don’t see how backend WF will help on that. You could read @petter ultimate guide to Bubble performance and there’s a lot of topics about that on the forum. Finally, last option could be to move to an external DB solution… But again, in most case there’s way yo reduce WU by reviewing your searches and DB structure.
The Hybrid Data Structuring approach it makes simple to implement enables you to have searches that cost 95% less workload units, makes searches performance 30-50% faster and allows bulk creation of data to cost 99%+ less workload units.
Better than an external database as it is all in Bubble so absolutely no headaches around user authentication or anything like that. And definitely provides the most up to date approach for how to optimize for workload units.
I got your plugin, and I’m very excited about the possibilities of reducing my workload units.
I have been going through your tutorials step by step, but I am having some difficulties:
In tutorial #5 - Get Data into Legacy - the initial API call for bulk creating contacts keeping giving me an error when I select Initialize Call, I get the error below:
"There was an issue setting up your call.
Raw response for the API
Status code 400
{“status”:“error”,“message”:“Unrecognized field: first_name”,“body”:{“statusCode”:400,“body”:{“status”:“ERROR”,“message”:“Unrecognized field: first_name”}}}"
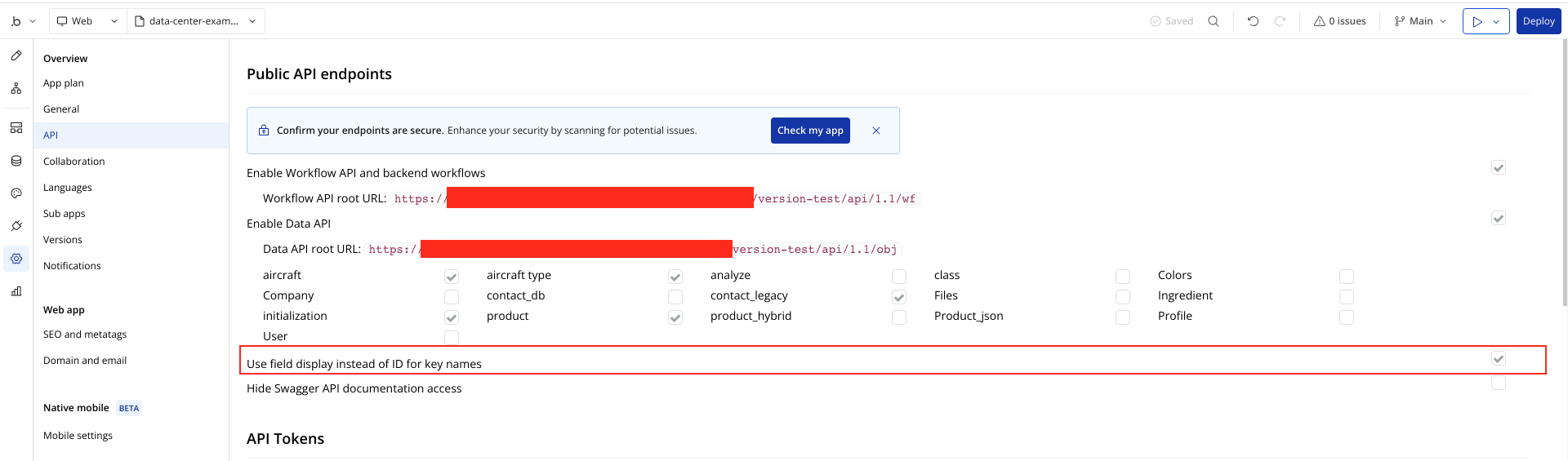
When setting up my Data_Center (amazing idea btw), what goes into the API call for “returned_values”?
Not sure if that’s the reason I get an error, but it’s not creating anything and I’m getting the error below in the debug.
When adding a property in the Data_Center to show a list of products, what exactly do I put in the default value? You said what you would put, but I’m lost on what you said, I do in fact need step by step instructions, lol
Is there any way you can set up a Demo Page that I can poke around in and compare to my app?
I appreciate any help, looking forward to getting this setup.
Are you attempting to just follow the video and do the same thing as in the video?
What is happening with the bulk create of things, the json needs to have the keys formatted exactly as the fields of the data type are. So for example, the error you see that says ‘unrecognized field: first_name’, indicates that your JSON has a key called ‘first_name’ but your Bubble data type does not have a field of that name.
However, another potential issue if your data type does have a field called ‘first_name’ exactly as the JSON key is formed, the settings in the app my not be using field labels and is instead using IDs. You should check the box to allow for field labels instead of IDs.
That setup there is for allowing you to bulk create things that will later need to be related to another thing. So, let’s say you have a data type called products, and another data type called store, and the store will have a field called products that is a list of the products data type (ie: related list field). It is the IDs of the products that get created via the bulk create call, that are the response of that call, with some other unnecessary values that Bubble adds into that response, and so we use the extract with regex to extract out only what we need, which are the IDs.
Those IDs can then be saved as a list of text on any type of data in Bubble (custom data type or api object) in order to have the list of IDs saved for the relation or be used in a custom data type for a field that is of type ‘product’ and not just text.
From the error in your screen shot, it seems like the extract with Regex is not in your app as the ‘unrecognized field name’ error showing ‘body’ is due to the fact that the ‘body’ field was not extracted via the extract with regex pattern in order to return only the IDs (bubble returns unnecessary details like body if you have checked the boxes on the api call to return errors).
(?<="id":")[^"]+
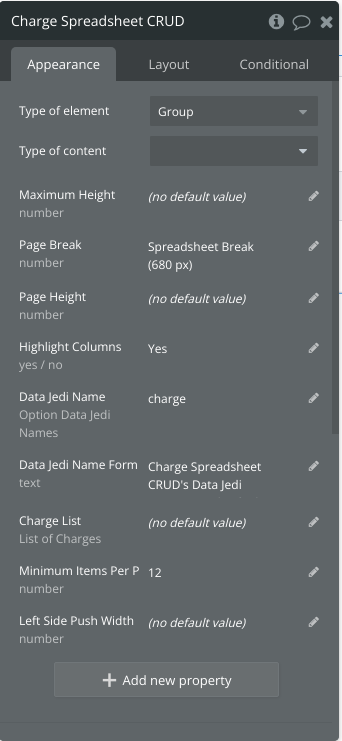
This is up to the app developer and what type of data they are using and how. Properties on the Data Center reusable are usually mean to allow for those values to be passed down to other elements outside of the Data Center.
So for example, the below screen shot shows some properties from a Data Center in an app.
The Highlight columns is just a yes/no value. It comes from the Local Storage Element on the Data Center, and so it’s default value is the Local Storage Value. That particular property and value is used to allow the app to store user preferences in Local Storage (other examples like language or dark mode) without ever needing to touch the database.
The other properties are for passing the data down. So some of the best benefits of using the plugin and the Hybrid Data Structure it makes easy to implement, is that you can download large lists of data at 95% less WUs, so, because it is so cheap, why not just download all that is needed, so that your app performance is as best it can be since all data is already available. It gives the best of both worlds and solves this problem of “I want fast performance, but WUs are too expensive to load data until the user really needs it, but if I wait to load data until the user really needs it, I lose performance as it will be slower to perform the operations compared to if the data was already downloaded”.
So as the user points out, they have a dilemma. They are not sure of what to do to build their app optimally, and using a legacy approach to building and data structuring in Bubble, you can not solve for that problem, but using a Hybrid Data Structuring approach, you do solve for that problem by making the WU costs an after thought (ie: solving a problem of WUs making it so apps can not be built optimally for performance and WUs at the same time).
So, in most of those properties, you will notice the default value is the Data Jedi Element Value List.
Then on other reusable elements, we can add properties of the same type of data but leave those default values blank in the reusable element itself, as we will, once placing those reusable elements onto a page or into another reusable element, set the property default value on the ‘instance of the reusable’ on the page or other reusable, and that value is coming from the data center property value.
With this method, you can just set up your Data Jedi Element to conditionally load only what that particular user needs during their session and nothing more and nothing less, and when that user is of the type that can access and use all data entries, just load it all (like admin users).
I have plans on releasing a lot of stuff like that to make it easier, but at the moment I have not been focused on it. My release of the plugin was earlier than expected, and I’m currently building apps with it, finding ways to improve it and making it simpler, more flexible and more feature rich. Once I have most of the elements, actions etc. in place, I’ll be putting together content to help others understand more easily how to build with it.
For example, I’ve been adding in a Data Download feature to export data of any type (custom data types, api objects, option sets etc.) in any form (text, csv, json, markdown etc.) which is the type of feature that will be in the Data Center, as well as the file upload functions to allow uploading of files to the file manager through a single element in the Data Center from anywhere within the application in the same way the CRUD operations are able to all live in the Data Center and be triggered from anywhere in the app.
Once I have those types of things in place, I’ll be focused more on the creation of content, guides etc. to help remove the cloud of confusion that exists around it all.
Thank you. This is something that has helped me build much faster than I ever have before. Based on the speed of development increases I’ve had, I’m putting a lot of effort into ensuring as many features/functions of the plugin that can be used via the Data Center, will. This is something that comes in the form of some newly added features of Structured Data elements that have conditional options to expose and inject the data or not based on which page or view (Single Page Applications) the user is currently on. In the process it also eliminates issues I’ve had personally with Bubble for years, such as how to provide the values for use in the structured data.
For me personally, I see the use of the Data Center as a way to make Single Page Applications even more powerful as it enables functionality that previously was nearly impossible, such as a SPA with top notch SEO, or easier methods to provide Google with custom sitemaps, especially useful for SPAs or multi language apps in need of SEO benefits.
This is a misrepresentation of that post. Has nothing to do with being “unsure.” It’s highlighting a fundamental programming tradeoff that goes beyond just Bubble.
I have a few questions as I’m piecing this together:
Data flow: It sounds like I should convert my existing Bubble types into API friendly JSON objects and store them in the new hybrid table for fast reads. I also want to be able to view my data in a readable format. In the video you showed converting back into the legacy format. Was that just for inspection or is there another reason to write into both formats?
Dual writes: When I create, update or delete a record, should I run two actions, one to write to the hybrid API table and one to the old Bubble type to keep them in sync?
Refactoring: Once my hybrid structure is populated, should I replace each page and workflow that reads the old data type with the new hybrid type one at a time?
Read only migration: Is there a way to use Data Jedi and the Data API to bulk migrate my existing Bubble records into the hybrid JSON format just for reading so I can eliminate Search for calls and save workflow units without immediately touching my legacy tables?
The hybrid table will make it so the data is downloaded around 30-50% faster than normal custom data types would be downloaded, and reduces the WU costs of retrieval by 95%. That performance improvement though, in terms of faster downloaded, is still hindered by Bubble implementation of lazy loading on Repeating Groups, so the actual difference in speed is usually 0.25-0.50 seconds, which for human eye is not noticeable by much, but can have a huge impact on how many visitors stay around until data is visible.
In order to view the data in a readable format, just add it to an admin dashboard page.
In the video I did not convert back into legacy format. In the video I demonstrated how to convert existing custom data types (legacy format) into the api objects for enabling the hybrid data structuring approach. There is no need to convert anything back into legacy as it already exists.
That is completely dependent on your use case of the app and the data itself. In most setups there would be absolutely no need to keep the existing custom data types at all, I only mentioned it in the video to highlight the fact that you do not need to delete them if you do not want to. I wouldn’t in most situations keep the custom data type and the new api Object hybrid data structuring approach, but in some situations I might, it all depends on the data and the use case.
As with anything in Bubble, it is important to use an approach suitable for the data and the use case. If I find there is no reason at all to keep the custom data type, I would not keep it, but if there was some reason to do so, I would then use a backend database trigger change to keep both tables in sync. You can setup backend database trigger change conditional expressions to use the API Object field values in the same way you would for a custom data type. I would run actions to update the api objects and use the backend database trigger change to update the custom data type, if the use case called for the custom data type to still be used.
Some reasons potentially to still use the custom data type is that you have a search, so show hybrid data structure api objects to get faster download and cheaper costs for showing the search, and upon a user selecting a particular item from the search, use the custom data type to show that selected entry. But in reality, you still wouldn’t even need to do that all the time, it is completely dependent on the data and the use case.
I wouldn’t replace anything. I would copy it to have an exact copy and then in the original I would remap all expressions to the new data structure.
Yes. Just do as in the video and recommendations in this post. As with anything in Bubble there are a multitude of ways to approach how to do something and for the most part, it all depends on the data and the use case. If you have a use case to just use the hybrid data structuring for searches only, then you’d just setup the app for that approach.
There are a ton of possible combinations of approaches to take, that is why the hybrid data structuring approach creates so many more opportunities of how and what to build in bubble. For example, I have an implementation of a full list of api objects saved to a single field of a single custom data type entry, as well as a custom data type that holds onto lists of api objects and the list of text that are the IDs of api objects related…this is due to how many data is related to each piece and the setup of the app and the features/functions that require me to setup my data in this way. This is just to exemplify that the type of data, and its relations and use case and features/functions of an app are important considerations when making decisions on how best to setup the hybrid data structuring.
The above example was setup in this way because in the app a user can create a shipment term in isolation from a list of all shipment terms which by default is not related to any other type of data. But a user when creating a new charge template can choose from lists of existing shipment terms to add to the charge template, select an existing shipment term and alter before adding to the charge template or just create a wholly new shipment term and add it to the charge template. My shipment term CRUD reusable is shown in isolation when user looks at the list of all shipment terms and also is nested into the charge template reusable when user is creating a charge template.
It also allows a user to remove shipment terms from a specific charge template or delete the shipment term entirely…there is a lot of considerations to make when deciding on how to optimally structure the data for the features and functions of the app.
Thank you for your detailed reply. I was confused because in your videos you sometimes show data being created and saved in Bubble’s legacy database format, but I now understand you recommend using only the API Connector’s data, and that makes much more sense.
A few more questions:
1. In the Global Data Center tutorial you perform create, read, update, and delete against the legacy Bubble database. How do I perform those same operations directly through the API Connector instead?
2. Can I create or edit API Connector data in backend workflows? In my app I need to update records automatically when a Stripe payment succeeds and I already trigger a backend workflow on that event.
3. What’s the best way to apply filters so that items are already pre-filtered before the page loads?
Those CRUD operations are using the Bubble API for custom data types, as it is cheaper than the in editor workflow actions. They are not used in conjunction with api connector objects as Bubble doesn’t support the creation or modification of api connector objects stored on a custom data type through the api.
Yes, there is a server side action in the plugin for that. There is another that allows you to compare two lists of objects as well.
You can not pre-filter before page loads as in the sense of only returning from the server the specific items you need, since the server doesn’t support filtering server side on api objects. The general concept is that you use non-sensitive, public facing, high searched data sets that can be fetched from the server and on the users device so cheaply, that it doesn’t really matter how much you are returning. But as with everything, developer must think through their use case and apply an understanding of how to best setup for their use case. For me, this means, being able to understand how to categorize the data so I might not need to filter what was fetched.
But api connector object data is like any other in bubble when it comes to filtering on the page, so once it is on the page, before it is visible through elements to the user, you would already use the same dynamic expressions and constraints and sorting options as you can with any other type of data.
For example, I use the dynamic sort by (ie: sort by ‘change which field’) and I use this with an option set that is the list of field names of the api object.
But if the concern is about Privacy and not wanting a technically inclined individual to find the data via browser console, then you need to apply concepts to protect the data for that type of data. For example, in Bubble, the only real thing that is needed to be known about protecting data, is to use Privacy Rules, so if you are using data as API connector objects and need privacy rules, then just create a custom data type with two fields as list of objects, one list of objects has all fields, and the second list has only the fields for a specific privacy rule, and then in privacy policies on the custom data type, set the privacy policy to restrict access to the field that has the list of objects with all fields on it. That acts as a sort of second layer of security in addition to the privacy rules…or just create two separate entries in the DB of the custom data type and one entry is list of all fields and other has objects with only certain fields, add a field to denote which is which and setup privacy policies to match.
Hey @totalsportshub01
While I support using a plugin like @boston85719 's where it makes sense - and it sounds like a great plugin btw - Bubble can, in many cases, handle scenarios with it’s “out of the box” features.
When I find a scenario when my first attempt yields slow/expensive searching, I look to restructure the data. Here are a few general ideas.
a. You need to use keys (e.g. a child data type has a field of the parent data type) instead of searches based on text comparisons (e.g. field contains/doesn’t contain text)
b. You can hold a “list of” children rows on a parent data type and this may prevent needing to do a search in the first place, as the list of children is known already, and you are simply retrieving known records (by a list of keys) from the parent row instead of searching.
c. Using Option Sets to categorise data is better than using text based comparisons.
d. If you start to use (i) searches within searches [e.g. select X where field A contains (select Y where some criteria)] or (ii) “advanced” in filtering, or (3) using group by, will be slow/heavy. Consider pre-processing some data so you can rephrase your search with no nesting or advanced filtering.
e. Unlike a classic relational database, sometimes duplicating fields in different tables can significantly improve performance. It may not be elegant, but it works.
f. Doing anything like running 1,000 records through an API workflow, one at a time, and doing a bunch of searching and data manipulation for each record, is always slow and expensive. Avoid it, and consider a plugin or external tool like Make, a different database, or @Boston’s plugin - once you have done the simple things listed above.
If you do have a lightweight need for this kind of processing in a Bubble app, I still support that, and you could deftly pre-process the data either when it is stored initially, or put it into a reporting style datatype, and run that report sparingly say weekly/monthly- decoupled from the main datatypes. But remember, Bubble is built for web apps, not to become a data warehouse. Keep in mind to use the tool the way the tool is meant to be used.
You can probably tell I have an odd obsession about database structures… I blog on the topic here.
Not exactly. You can use the API objects or plugin objects even if the records need to be updated, as the plugin is built so as to provide the necessary actions to perform all create, update and delete actions on the API objects client side, before updating the DB to store them. Additionally, if you are storing API objects in the database and they are updated, the updates are reflected for other users in real time exactly as updates to custom data types are, so there is really no difference whatsoever in terms of what you can do with API objects compared to Custom data types in bubble. You can even use database trigger change events on fields of an API object stored on a custom data type which gives even better granular control over when to execute those database trigger change events since you are basically triggering it off of a ‘related object field’ and not just a field on the custom data type itself.
As with any database structuring, it is important to consider the type of data and how it is used to determine the appropriate data structuring approach for that data. The Hybrid data structuring approach just opens up so many more options to choose from in order to structure the data optimally for the app use case and the specific data use case.
For example, a data set that has 10,000 items and is rarely updated, I would not save this as a list of API objects on a custom data type field because of the 10,000 items max capacity of list fields. Instead I would save it as a JSON file on an option set, and when using the elements within my plugin, you can serve to the user the 10,000 items without touching the database to retrieve the list as it is an option set, buy you are still charged WUs for hitting the API, the costs of which are tiny when compared to the legacy approach of searching for 10,000 items of custom data types, mostly the savings comes from not getting charged for 10,000 items and getting charged less for each character returned as the number of characters returned is far less than if you were to return a custom data type with the same exact data and number of fields because Bubble does add prefixes and sometimes suffixes as well as doubles up on some fields.
There are multiple ways to leverage storing information in Bubble with the hybrid data structuring approach that are just not possible with the legacy data structuring approach, and way way cheaper, so apps can actually scale on Bubble without having to increase their monthly subscription fees so quickly. For some businesses this can be the difference between having enough runway to bootstrap and scale or failing because of lack of financial resources.
That is the only way. If you use the Get API call it is basically same costs because the Do a search for hits the API the same way and the API call returns the data in the same way. However, with the plugin or setting up API calls on your own, you can save WUs on creating or modifying entries as those API calls do actually cost less than the workflow actions of create a new thing or make changes to a thing.
This is a good point. The way bubble works, if you have a data field on data type A that is a list of another custom data type B, Bubble will just basically store the IDs of those related things (data type B), and when you search for data type A will not charge for returning all of the related data type B unless somewhere in the repeating group where data type A is searched you are referencing a field value of data type B. And when they do need to return those related things, they basically just charge for individual data requests, I believe, as they are performing a search behind the scenes using the IDs of those related things which when we search by unique ID we get charged only for an individual data request. I think you can achieve the same thing by saving only the related data type B list of unique IDs as text on data type A and when you search for related type Bs, can perform Do a Search for with constraints of unique ID is in ‘related field list of ids’…so it makes sense to just use the related data type anyway, as Bubble smartly handles that for us.
So much easier to maintain and make some changes when needed as well
Depending on the size of the list of Group by it might actually be faster than Do a search because as @georgecollier pointed out in a post the Group by will only return those related things in the groupings and not all things, making the amount of data needed to download less, and so therefore faster. But on larger lists of things, it is possible that the group by is slower.
This is true. It does though pose the issue of needing to keep those fields in sync across two different data types which adds to WU costs, but if the point is to just reduce speed to filter by removing a need for an advanced filter it is good to do. What I have began doing with use of my plugin is store those types of objects on the main data type as a field that is the api object, so the field is not really doubled up across two different data types, but is on the one data type as part of the api object. It still requires the use of an Advanced filter, but seems to be faster compared to if the api object was instead a related field of another custom data type, I think because the api object is on the actual custom data type searched and filtered. I have not tested this against large lists of things, so might not that much faster, but it is removing a need for two separate data types.
Yes, this is a great use case. With my plugin you can (even if still working with custom data types) use it for the purposes of making all the changes client side, in bulk and then just saving it back to the database. So for example, if using a custom data type, can use the plugin elements to work with them as api objects for client side processing, and then use the exposed state of bubble ready json api to then run an API call to update them in the database. Or if working with API objects, again just use the elements and the actions to update all 1,000 objects client side and then save the exposed state value list from plugin element to save them into the database.
The plugin does have server side actions as well to process large lists and have 4 exposed state lists available, the full list, newly added list, modified list, and unchanged list. Since the large list is updated in one server side action it removes any need to use recursive backend workflows to update large lists and the run backend workflow on a list, so compared to both legacy approaches saves considerable amounts of WUs to process large lists.
I personally have come to understand building apps as basically shuffling data around and presenting it in different views and allowing users to manipulate it as they need. Most of what I think apps do is just CRUD (Create, Read, Update, Delete) data. So in Bubble we use our data warehouse to enable users to create new data and store it in the warehouse, retrieve the data from the warehouse, make updates to that data once retrieved and then update the data warehouse with the updated data, and to delete the data from the warehouse.
The goal is to make the UI (how you present the data from the warehouse) easily digestible by the user, and the UX (the way the data from the warehouse is manipulated) easy and intuitive for the end user.
But, it is true that Bubble does not have the most efficient database, and so if using extremely large sets of data, it doesn’t perform as well as alternatives.
Our datasets in Bubble do not need to be very large before they become very costly. For example, I have a data type in an app, of which it is only one of many types, but is a type that is in the app for the purposes of drawing organic search traffic from Google. This data type has 2,000 items with only 6 fields (it used the legacy approach of satellite data type to improve performance around the search). That one data type every month costs between 150,000 and 200,000 WUs to support the 25,000 - 30,000 searches performed each month. Keep in mind, I do not promote this app, and just allow it to sit as is. When I implement the hybrid data structuring approach to replace this data type, my WU costs are between 7,500 - 10,000 WUs to provide my users the same exact functionality and data, with the bonus of my SEO lighthouse scores are improved, which may or may not result in an increase in the amount of organic search traffic I receive from Google. With that savings I am free to choose to reduce my Bubble subscription cost or use those saved WU resources to add more features that provide more value to my users, likely resulting in an increase in revenues for the app.
Got it. Yeah, I’m not a trained developer, I’m from the design side, so I’m still getting the hang of things development side, but loving the challenge. Thanks for the detailed explanations, very useful seeing how you guys think.
@boston85719, Sorry to be this guy, but would it be possible to get a tutorial for crud operations for API objects? I’ve gone over all your current tutorials a ton of times already and still haven’t figured it all out and would love to get up and running.
Please let me know what you would hope to see specifically in the tutorial. For me, I would likely just showcase an already built example and walk through what it is doing, so as to bypass any need to include simple things like how to setup the elements.