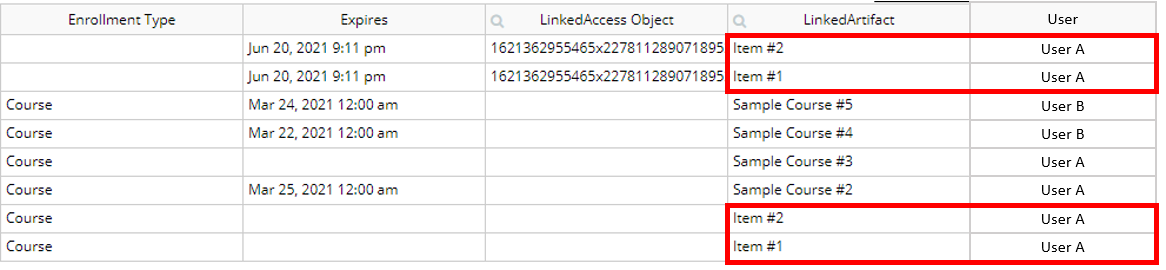
Greetings, all. I have a list of things in an RG that record entries when people purchased a specific product. While each thing is unique, the product purchased may repeat for a certain customer. I need to create a list of things that show the most entry for each product to remove older duplicates.
@eve, thanks so much for replying. Unfortunately, I wasn’t able to use the :unique items operator on the purchase history dataset as it kept returning the unique purchases (which was all of them) but didn’t support designating specific fields for duplicate evaluation such as show unique things ONLY based on repeat values in the Item column.
Other tools I’ve used support this kind of “selective de-duping” (feature request in the works? ). Bubble’s Group By is the closest equivalent, but sadly, it then left the data aggregated and inaccessible because it changed the rg’s data type.
I finally figured out a workaround by:
Creating hidden repeating groups that contained the filtered results for each filter category (e.g., Active, Expiring, Expired).
Setting the main rg to conditionally toggle between which hidden rg it referenced when a user makes a filter selection, thus ensuring it didn’t re-run a search.
Setting the rg’s data source to the products linked to the purchase history and only THEN applying the :unique items operator.