
OK, so here’s the lazy person’s way to do this. First, you must define your Things (seems you might have already done this, but just in case). The data model I’m using for this is this github repo: GitHub - abhionlyone/us-car-models-data: Introducing the most comprehensive and up-to-date open source dataset on US car models on Github. With over 15,000 entries covering car models manufactured between 1992 and 2023, this repository offers valuable information for anyone looking to incorporate car data into their applications. Best of all, it's completely free to use!
And in this model, a “vehicle” looks like this:

So, we need a thing (custom data type) for Vehicle, Make (I’ve called mine Vehicle Make so I can just get rid of it later), Model (mine called Vehicle Model), and Body Style (Vehicle Body Style for me).
We can make them like this:



And, once we have those, we can make a Vehicle:

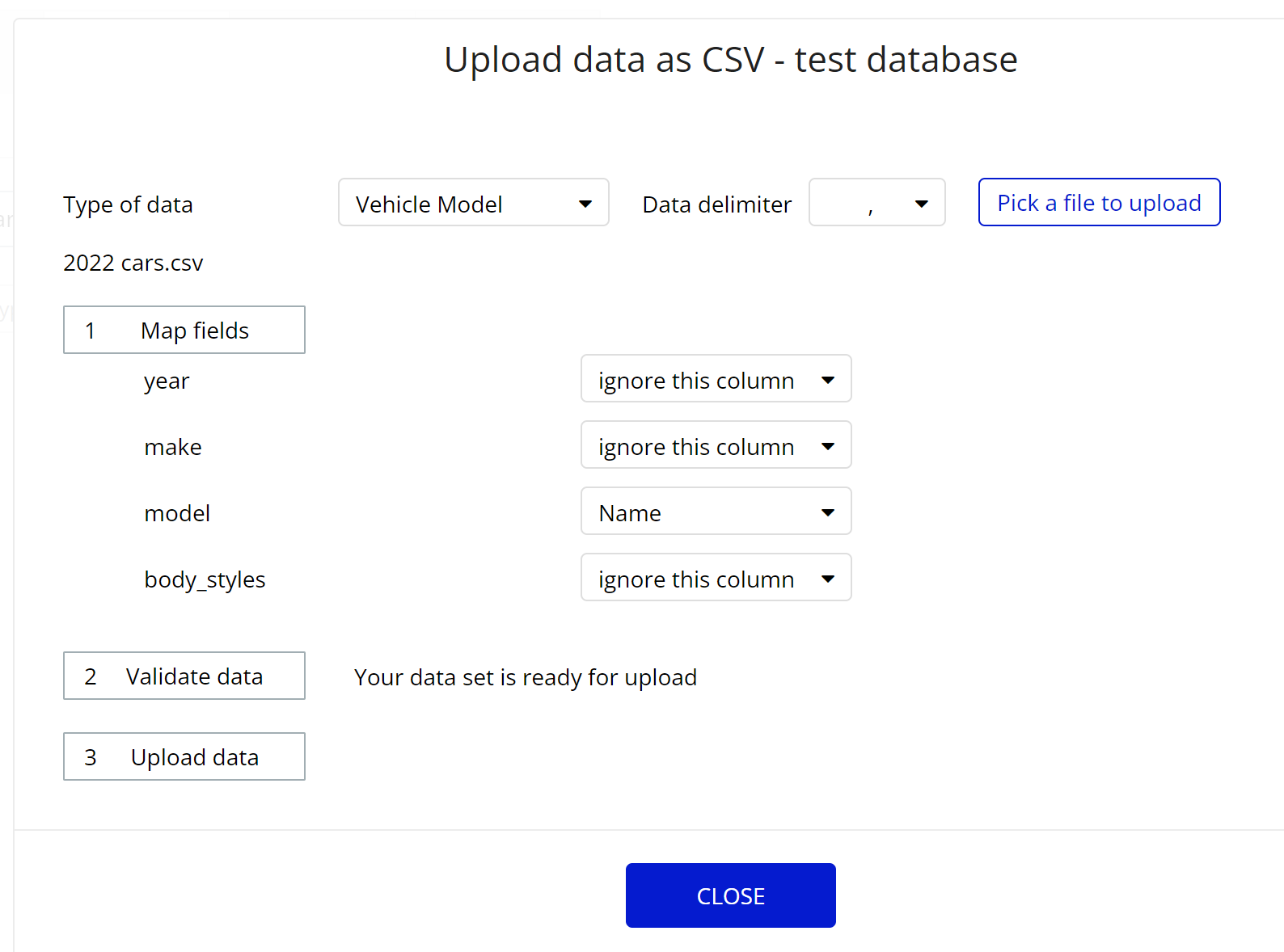
And now, to populate our individual sub-things that compose a Vehicle (which we must do first). I can take the 2022 cars.csv file (that’s all I’m using in this example) and populate (for example) Vehicle Makes like so:

And, when this finishes, I have some duplicate Makes, right? Like so:

I could have made a unique list of makes, but I’m too lazy to mess with Excel right now!
But now I don’t care because I’m lazy and I’m just gonna delete the dupes (preserving just one, perhaps the first one we created - or at least, the first one that shows up when I do a Search for them - it really doesn’t matter).
And I could do that many ways, but I’ll do it like this, I’ll just create a recursive backend workflow that (1) takes a list of texts that represents the unique make names, (2) pops the first unique name off of that list, (3) searches for all Makes with that name, (4) saves one of those Makes and deletes the rest, and finally (5) calls itself again with the remaining unique Make names.
Sounds hard, right? But my List Popper plugin makes this EZ-peasy.
Here’s what that “dedupe makes” of those backend workflow setups will look like:

And inside it I’ll do this (List Popper and Flow State are from my List Popper and Friends plugin) (forum thread here).
-
Put the Make Names (this comes from the API workflow call) and put it into List Popper.
-
Get all of the Vehicle Makes that share the Name that we popped off the list of names with List Popper (this is the first List Popper’s “popped item”). Now, I didn’t have to do this expression in FLOW State, but I find it conceptually simpler (and the “code” is easier to read). All this does is “hold” this expression here so I can reference it in the next step.
-
Put the Makes from step 2 into a second List Popper. This List Popper will take the first of these Makes off of the list and pass the rest of them to its “Remaining List” output. (So, basically, I preserve just 1 Make and pass all the dupes off to the next step where we will kill them. (Poor Makes!):
-
Delete the Makes left in the second List Poppers “remaining list”:
-
Call the workflow again, using the remaining list of unique makenames (held in the List Shifter from Step 1):





And so that workflow will take the NEXT unique make name and do the same operation that we just did on the first one. And the cycle will continue until we are out of unique make names whose Makes we need to de-dupe.
And to kick that off, I just make a little admin page and drop a button on it with a workflow that kicks off the dedupe process (sending it the unique list of make names in our database):


If you have a different data model, you would do the same sort of thing for each and every data type that might have dupes. (Which is to say, you can create them from a CSV where the type is represented uniquely, or you can just let it rip and dedupe them using the process I show above.)
Now, in the data model I picked, Vehicles just have a Make (which in my csv had dupes), a Model (which in my csv is unique) and Body Styles (which I’m not going to bother doing because this isn’t my damn app, it’s just a demo.
So now I uploaded my Models like so:
And now here’s all my Makes and Models in my database (visualized in some RGs on some random page):

And now (since I have a unique set of Makes and a unique set of Models and I’m ignoring “Body Styles”), I’m totally ready to use that same CSV to make my Vehicles:

Note that, now that Makes and Models exist, I can reference them BY NAME on import.
And now, you see, my Vehicles are associated to the THINGS for Make and Model in my database:

(I didn’t bother to cross-associate Models to their Makes because (1) I don’t care to do that and (2) it’s not my app and (3) I’m just trying to show how you do this with a simple example. But of course we could do that if we want to now, just by traversing Vehicles.)
And now let’s look at a more sensible view of our Vehicles in an RG:
EDIT MODE:

RUN MODE:

And these Vehicles are are proper Bubble things with unique ID references to unique Makes and Models.
Anyway, that’s the basic process you’re going to have to follow. But it’s pretty easy. I didn’t know anything about doing this and it took me longer to write this post than it did to figure it out from the interface and RTFM.
Obviously, populating databases isn’t the most fun or glamorous part of creating an app, but it must be done in some cases.