I am new at bubble and read few topic related to SEO but didn’t found questions similar to mine.
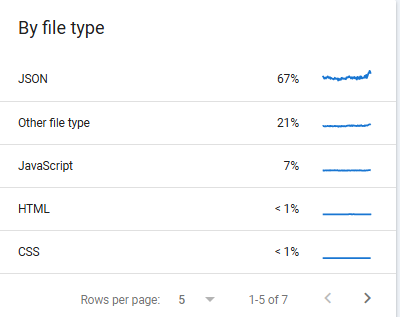
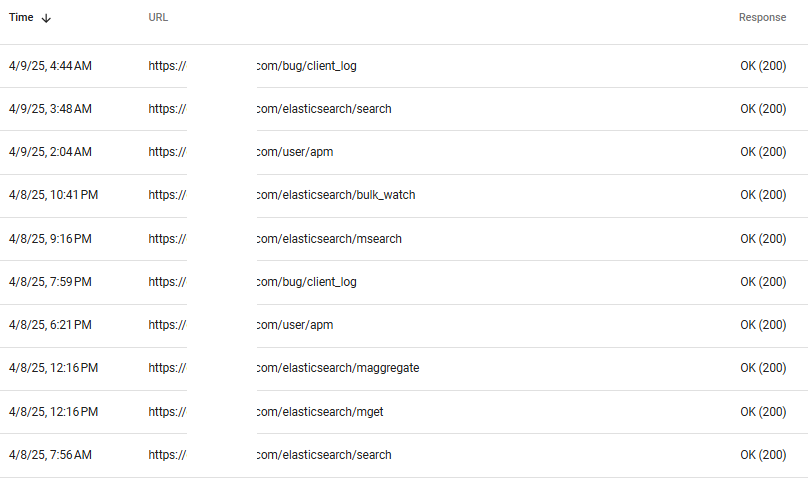
I see in crawl stats in Google Search Console a lot of requests to JSON files
Hey @whiner, I would recommend not blocking Googlebot (Google’s crawler) from blocking the resources mentioned in your screenshot. Those resources are critical for displaying the dynamic content for your bubble application. Blocking them via the robots.txt would basically prevent the crawler from being able to download the content full version of your bubble app (blocking those resources may also lead to weird issues in how the app would be presented). Generally there’s no reason to worry about these resources since they will not be placed into Google’s index.