So we have been getting an enormous amount of workload units being used for one specific step in one specific workflow.
Initially, we thought it was because we were doing multiple searches of large datasets (60,000 at the time of writing) in that one step. Obviously room for improvement right?
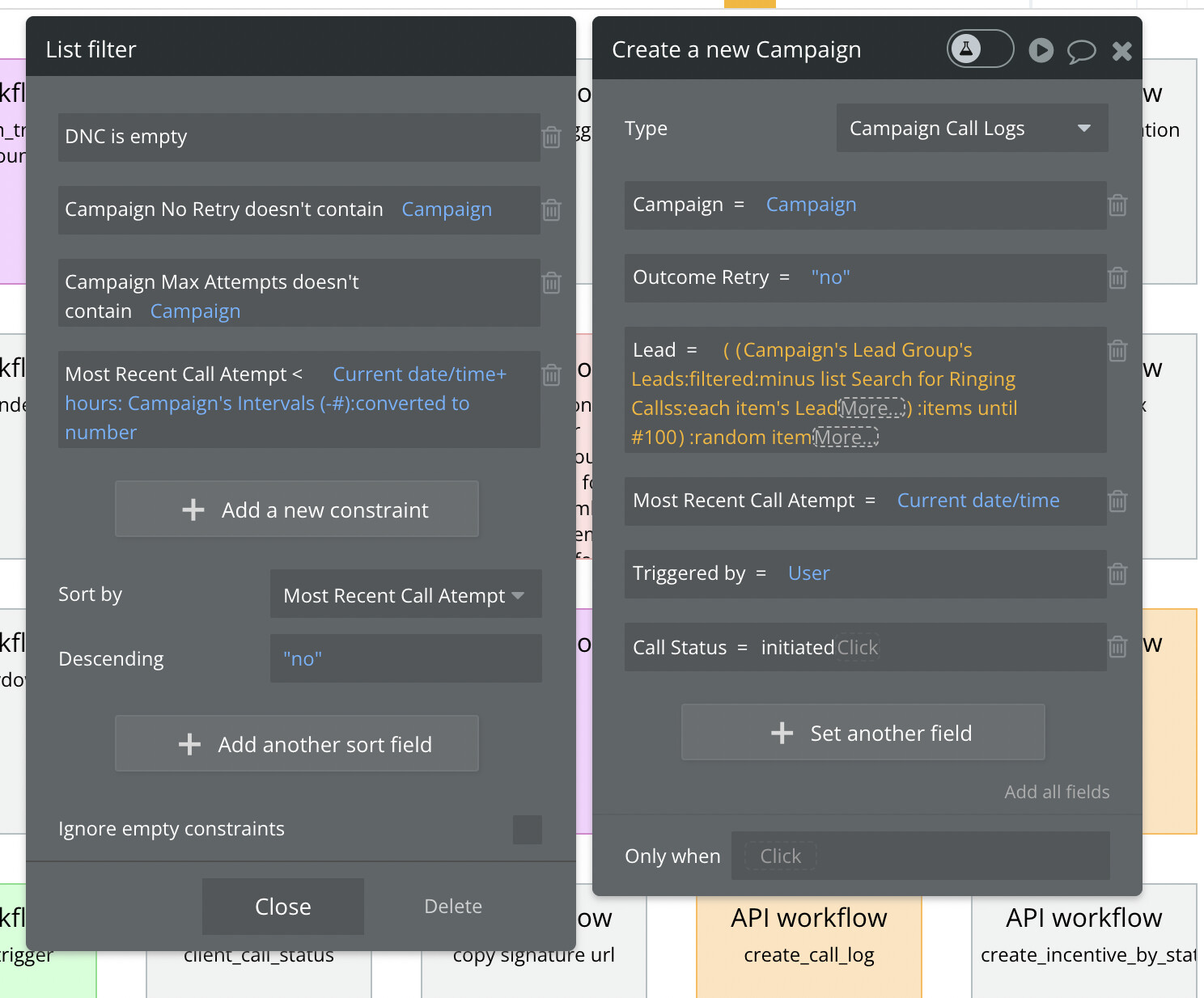
So we optimized, used data triggers to dynamically gather data to reference instead of searching for entire lists, etc…
We eventually got the search down to one single search with filters/conditions. However, this really doesn’t seem to have helped.
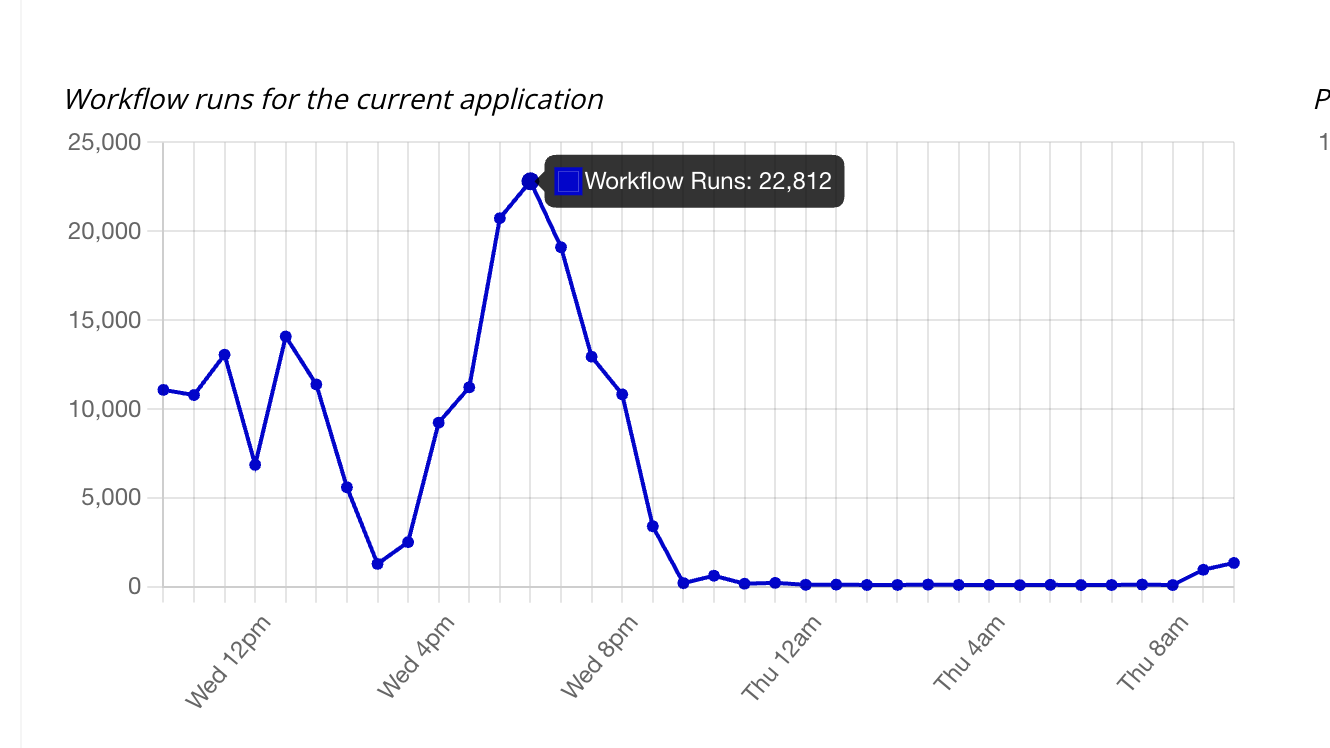
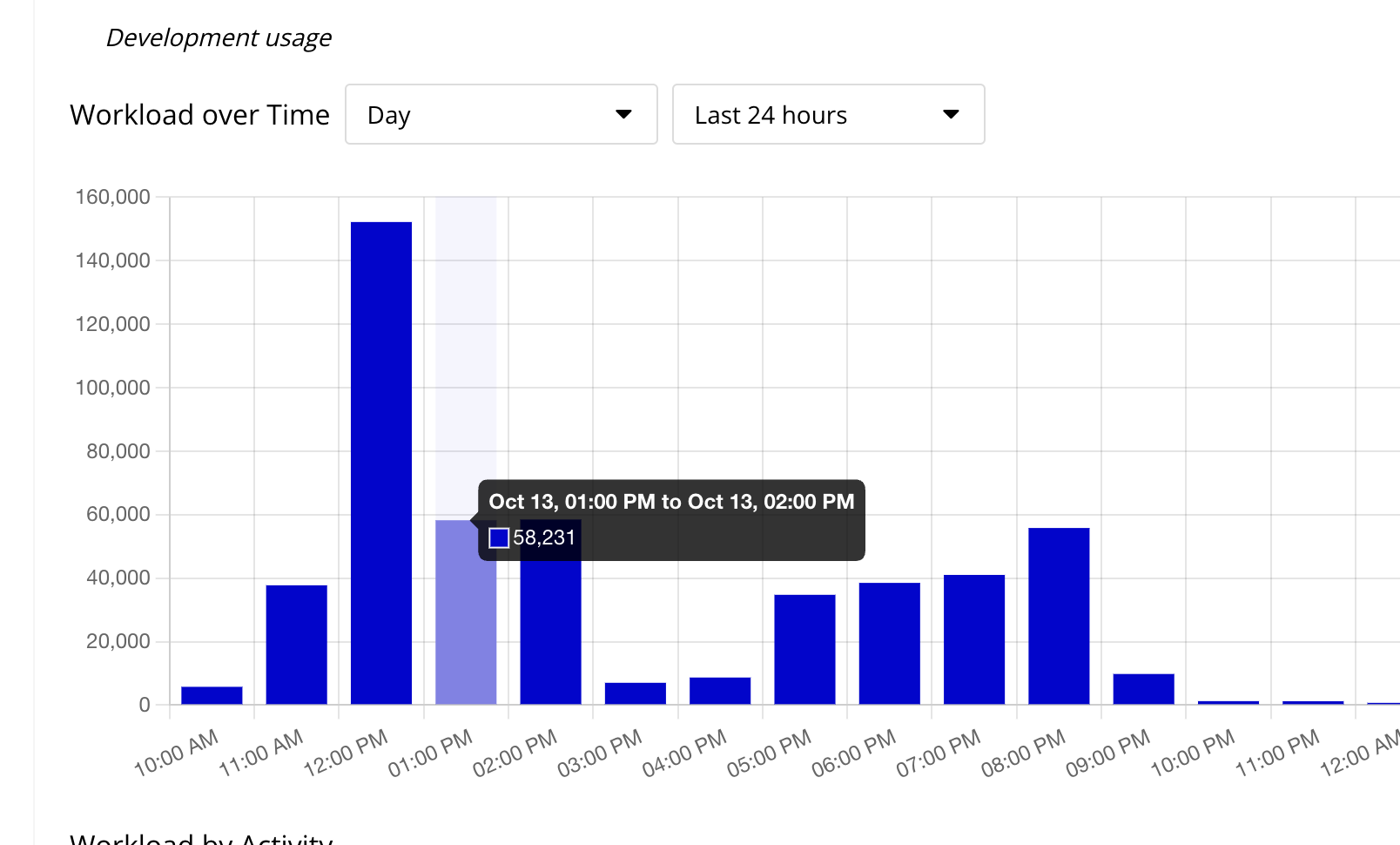
Below are screenshots of our app metrics. Yes, you can see that correctly - 10,000-20,000 WU in a single minute is not uncommon if 5-10 users are actively using this one feature/step at a time.



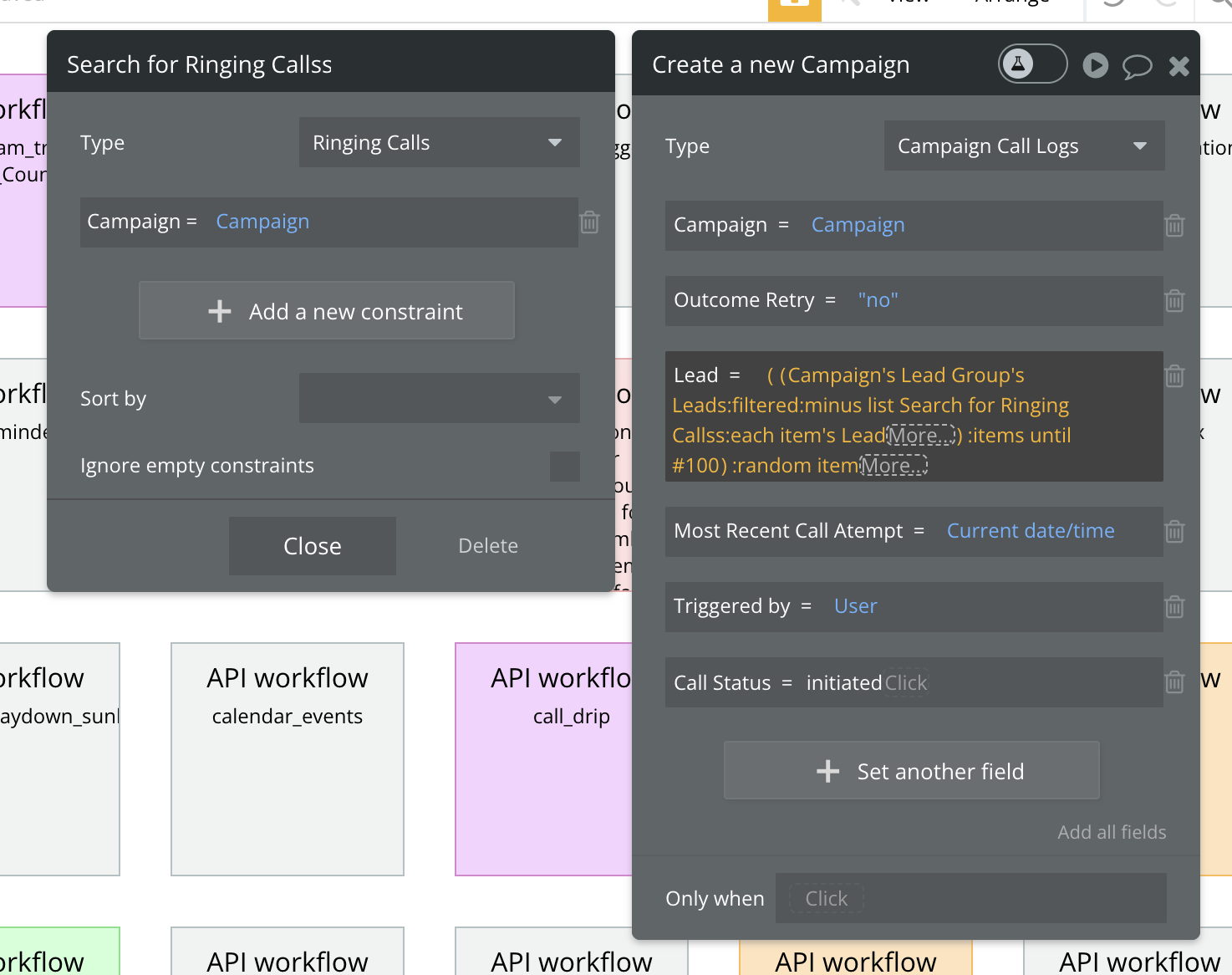
And here’s the single step that app metrics is telling us is using a vast majority of the Workload Units:

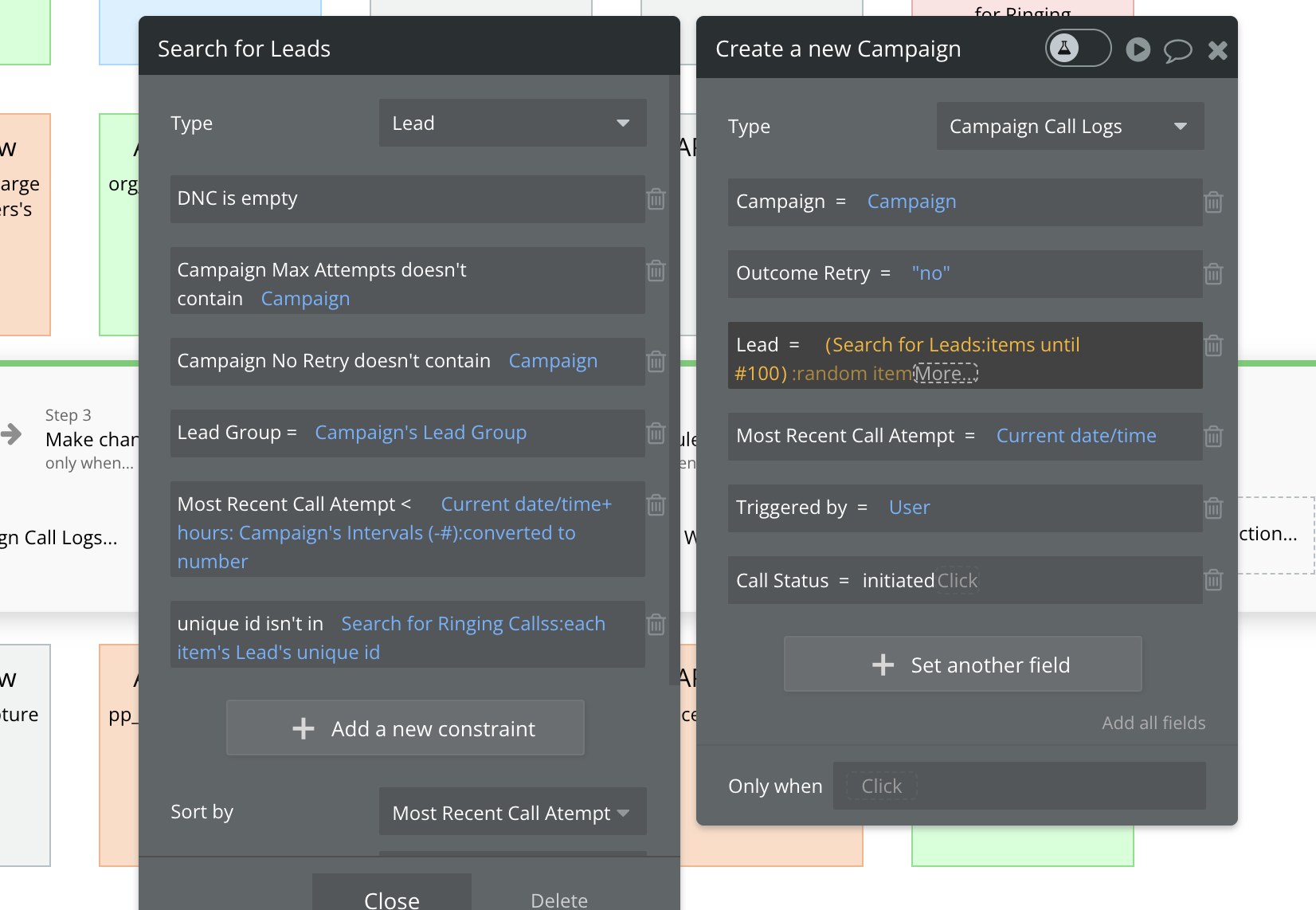
The singular datatype search we managed to condense the step down to must be the problem, right?
The “Lead” datatype is being searched. The lead datatype in total has 275,000 entries, but the filters / constraints brings that down to less than 10,000 and then we just grab a :random item from that list. We are not using any “:count” endings for the lists/searches which I know can drastically increase workload units…
The strange thing is, from the optimization we’ve done, the workload units have already drastically decreased (not nearly enough, but definitely decreased). The one issue that still remains is the total amount of workflow runs. We have a loop step at the end with a 3 second delay, a hard constraint, and also a “result of step…” in one of the fields (which I believe forces it to wait for that step to finish?).
To me, it seems that step 1 (which has the initial search) is not returning a result and therefore looping thousands of times until it does. The rest of the steps in that workflow have a condition (do not continue if result of step 1 is empty) which may be why they also aren’t running thousands of times, but if step 1 is actually returning an empty result we should DEFINITELY see that in the server logs?
We’ve also added a step to change a specific field in the datatype entry that step 1 creates IF the result of step 1 is empty. That way we can see in the database new entries being created if the result of step 1 is empty - but there’s nothing being created which I would assume means that that is not the issue…