I’m publicly releasing these three small plugins that are based on open-source Node.js modules. I had to implement these actions for my latest back-end workflow project. Each one contains a handful of useful Server Side Actions:
Tired of inscrutable hacks to get data out JSON returned by third part APIs? Need the extra firepower of recursively searching JSON? Well look no more. Newly add to the Bubble Back End Utilities: Extract serialized JSON from serialized JSON using JSON path queries This small update adds the JSON Path Filter server side action. This action wraps the query() function provided in the jsonpath Node module.
I downloaded your plug-in, thank you for your work.
I am trying to use it but without success.
My use case is as follow:
my user selects a PDF file from the database project.
then he enters in “an input” the page(s) he would like to extract from the selected PDF
then he clicks on a button “save” that triggers a workflow
I would like this workflow to create a new pdf file with only the page(s) selected.
I cant’ figure it out how to create this new pdf using your plug-in, please let me know how to do it.
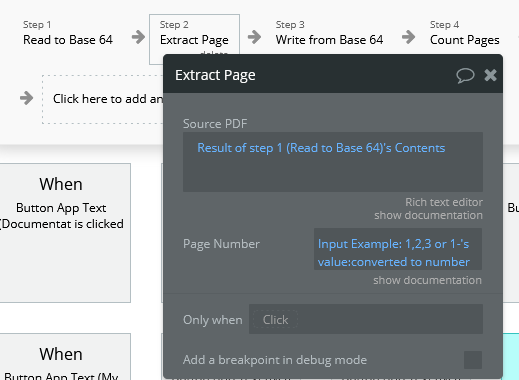
Thank you for writing. Because of the way Bubble handles files the output contents of the plugin is a bit tricky: it is the PDF encoded in base 64. Once you have the output contents from Extract page you will need to save it as a Bubble file. For this I wrote a small plugin of back-end utilities. It contains an action Write from Base 64 that accepts a file name and contents field. The output of that action is a Bubble file which can be stored in the database.
Likewise Merge Pages expects a list of Bubble files.
I extract the page selected by the user. Btw, how many pages can we extract ? If I need to extract the page n°1 and the page n°6, how it should be specified ?
I write from base 64 as you mentioned in your comment. Beside, what is the Home URL ? The home url of my website ?
The error you are facing is because Bubble passes URIs (URLs) for their own S3 stored files without the protocol prefix https:. There are two solutions to this:
The first is to not use the Read to Base 64 and instead in the Source PDF of theExtract Page action simply put the Dropdown App Test (Select a f's value's Original file : encode as base64.
Or you can use the Read to Base 64 action supplying the prefixed the URL https:Dropdown App Test (Select a f's value's Original file 's URL to the action. But honestly the Read to Base 64 was intended for accessing external resources, not files already saved by Bubble.
You can extract all the pages with the action Extract All Pages which returns a list base64 serialized PDF’s you can then pick and choose which every list items you want (for example in a recursive workflow).
Yes the home URL is the home URL of the app website and is available in the context list of the dynamic value.
So i tried to set up the workflow to merge the pages the user selects.
I am doing this with an API workflow.
Basically, in the API I each iteration is as follow:
a) I extract the the page “1” with your plugin
b) I write from base 64
c) save the page extracted in a DB field (type of the field: list of files)
d) I increment the page to extract
I do this until i have extracted all the pages selected by the user.
The next step after the API workflow is to merge the list of pdf pages extracted.
I don’t know why but the “Merge pages” pdf I get is empty only 1 white page.
However when I check the DB field where I store the list of each page as a single pdf, I have all of them.
Do you know why ?
It is me again. When you have time, could you show me how to use the merge pages feature, I tried everything but I still can’t merge
I am using it in a API workflow and tried also outside the API workflow.
Hi @aaronsheldon ,
Thanks for the plugins developpement work!
I have loaded your Bubble Back End Utilities
Indeed, i want to post an audio file, recorded in bubble, to a third party API
I got the point that Bubbles only deals with S3 url’s, which is an issue to post files to API’s
I guessed, but not sure it is correct, that I have to turn my audio files to an UTF8 format, as “raw” works in Postman.
Therefore, i created this workflow:
You are very close on this one. You can save arbitrary binary to a Bubble file. up to a size limit. But…you have to convert it to URL safe Base 64 so that it can be incorporated in the POST request that creates the file on S3. The RESPONSE from the POST will be the URL of the file on S3.